라인
Pushsphere: LINE 메신저의 빠르고 신뢰할 수 있는 대량 푸시 알림 비법
Else
이 글은 Tech-Verse 2025에서 발표된 Pushsphere: LINE의 신뢰성 있고 신속한 대량 푸시 알림 비법 세션을 글로 옮긴 것입니다.안녕하세요. LINE Plus ...
2025-11-13
국내 IT 기업들의 기술 블로그 글을 한 곳에서 모아보세요
이 글은 Tech-Verse 2025에서 발표된 Pushsphere: LINE의 신뢰성 있고 신속한 대량 푸시 알림 비법 세션을 글로 옮긴 것입니다.안녕하세요. LINE Plus ...

JetBrains는 작년에 이어 올해도 한국의 고등학생 해커톤 ‘하이톤(HIGHTHON)’을 후원하며 인연을 이어가고 있습니다. 올해 11회 하이톤에서는 참가자들이 AI와 함께 변화한 개발 환경을 해커톤에서도 충분히 활용하길 바라는 마음으로 JetBrains IDE와 JetBrains AI가 사용 가능한 라이선스 지원이 이루어졌습니다. 참가 학생들은 ...
1990년대부터 현재까지 우리나라 환경정책의 변화 과정을 연도별로 살펴보고, 최근 환경정책의 패러다임 변화 경향을 심층적으로 조명합니다.
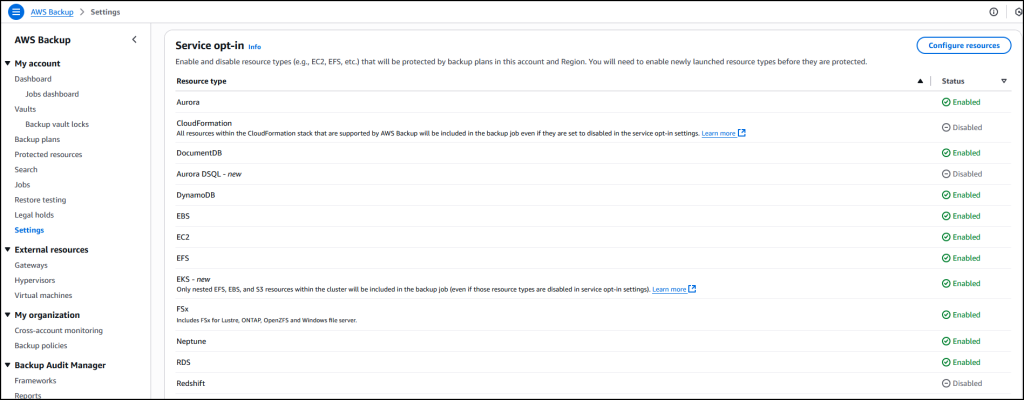
오늘은 AWS Backup에서 Amazon EKS를 지원한다는 소식을 알려드립니다. 이 지원을 통해 기타 Amazon Web Services(AWS) 서비스에서 신뢰하는 중앙 집중식 플랫폼을 그대로 사용해 Kubernetes 애플리케이션 보안을 확보할 수 있습니다. 이 통합을 이용하면 컨테이너화된 애플리케이션을 보호할 때 수반되는 복잡성이 해소되고, ...

AWS re:Invent 2025가 단 3주 앞으로 다가왔습니다. 이번 컨퍼런스에서 새롭게 출시되고 발표될 내용이 벌써 기대됩니다. 작년에는 전 세계에서 60,000명의 참석자들이 네바다주 라스베이거스로 모였는데, 열기가 대단했습니다. 지금도 AWS re:Invent 2025에 등록할 수 있습니다. 12월 1일부터 5일까지 라스베이거스에서 열리는 이번...

[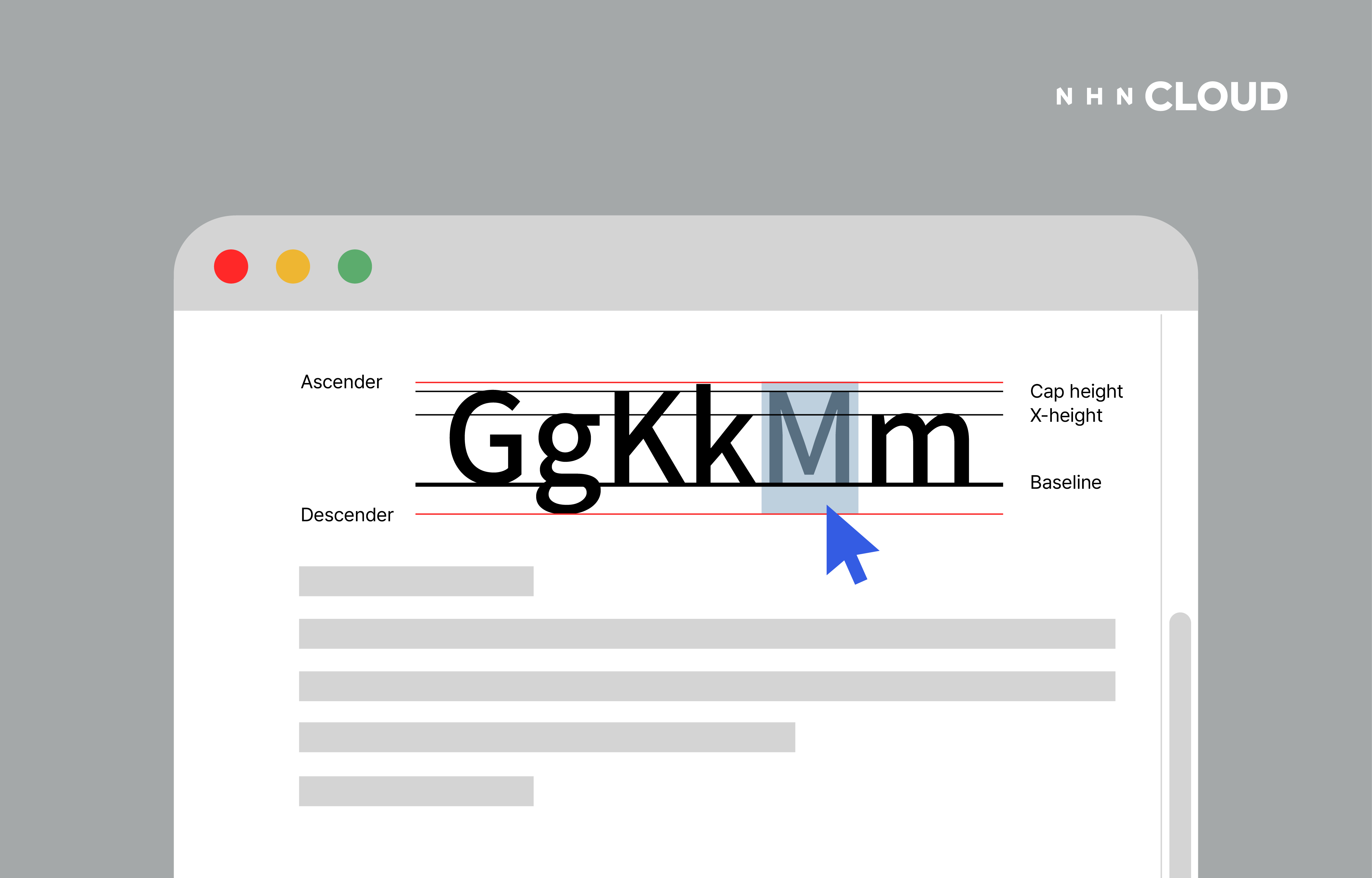](https://www.nhncloud.com/kr) 혹시 어떤 요소에 넣은 텍스트를 예쁘게...

들어가며 빠르게 변화하는 이커머스 환경에서, SDUI(Server-Driven UI)는 선택이 아닌 필수가 되어가고 있습니다. SDUI…

지난 25년 동안 JetBrains는 여러 프로그래밍 언어에 걸쳐 소프트웨어 개발 환경을 조성하고 개발자와 조직이 소프트웨어를 구축하는 방식을 지속적으로 개선하는 데 전념해 왔습니다. 그 과정에서 생산성과 개발자 경험을 향상시키는 데 꾸준히 중점을 두어 왔습니다. AI의 등장으로 이제 가장 중요한 과제는 AI 지원 도구가 현실 세계에 가져다주는 효율성...

그림 1. 특별상 받은 ‘팀 딸깍’ 인원들안녕하세요! 리멤버 개발실 백엔드팀 이형로입니다.지난번 ‘네이버 웍스 메일 가드’ 이야기에 이어, 저희 ‘팀딸깍’이 [제1회 리멤버 사내 해커톤]에서 벌인 또 다른 도전기를 들려드리려고 합니다.혹시 기억하시나요? 저희 팀의 모토! “AI로 얼마나 빠르게 많은 문제들을 해결할 수 있을까?” Amazon Q를 마음...
![[EVENT] 파파고 플러스 출시 1주년! 무료체험 이벤트 키링과 Npay 포인트 1만원까지?](https://blogthumb.pstatic.net/MjAyNTExMTBfMjg3/MDAxNzYyNzUxMDk1MTgw.adLfMsvAnAY0Lw87BRrzbBE7sVXIYv9hKcQA9NbNmCgg.0Et4fj-e_e1Wka5tA1YDkZgy6ZPUmzTqJVjd5Oj81Ecg.PNG/251110_papago.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com 입니다. 업무 속 번역, 더 전문적으로 사용하고 싶지 않으셨나요? ‘파파고 플러스’는 ‘파파고'에 업무 활용도가 높은 기능을 더한 유료 구독형 서비스로, 텍스트뿐 아니라 대용량 이미지, 업무용 문서, 웹사이트 등 다양한 형태의 콘텐츠를 서식 그대로 번역할 수 있습니다. 문서 ...
by 이스트시큐리티 마케팅팀 안녕하세요, 이스트시큐리티입니다. 국내 1위 PC 백신이자 1,200만 명이 선택한 국민 백신 알약이 더욱 강력하고 스마트하게 돌아왔습니다! 한층 진화한 차세대 통합 보안 솔루션 ‘알약 3.0’의 공식 출시되었습니다. 지금부터, 차원이 다른 보안 성능과 새로워진 '...

안녕하세요! 발레를 좋아하는 올리브영의 프론트엔드 개발자 개발레리나🩰 입니다. 마이크로프론트엔드(Micro Frontend Architecture,이하 MFE…
바이브 코딩의 기술적 특징과 함께, 개발자의 역할 변화, 교육 시스템의 과제 등 다각적인 측면을 분석합니다.
![[후기] LS일렉트릭-네이버클라우드와 함께 만드는 제조 AX (10/31 @역삼)](https://blogthumb.pstatic.net/MjAyNTExMTBfMTE4/MDAxNzYyNzM3MzQ5NjM5.Y-3DNqZfLzXuoj6eoOUlZGhZJs0ABRvGjMQqPFp0Lrcg.8kbXjsI4WAR5F__sEQr9jcK9Ox0sWy91LUpSRhO56eAg.PNG/lsencc_blog_thumb.001.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com입니다. ✨✨✨ 네이버클라우드 스마트팩토리 가이드북 시리즈 제조사와 클라우드가 만나면 어떻게 될까? 지난 7월, 네이버클라우드와 LS일렉트릭이 전력과 제조 산업 분야에서의 AX를 위해 업무협약을 맺었답니다! 설비 진단에 특화된 AI 에이전트를 개발하고, 스마트팩토리 솔루션의 클...

AI·데이터 기반 콘텐츠 기술 혁신 위한 핵심 인재 확보 The post 리디, 개발·제품 경력직 집중 채용…글로벌 콘텐츠 테크 기업 도약 appeared first on 리디주식회사 RIDI Corporation.
IP intelligence – F5 WAF for NGINX 활용 악성 IP 차단 구성 가이드 최근 웹 애플리케이션 공격은 단순한 취약점 스캐닝을 넘어, 악성 IP 주소를 활용한 자동화된 공격 시도로 발전하고 있습니다. 이러한 위협을 사전에 차단하기 위해 F5 WAF for NGINX는 IP intelligence 기능을 제공합니다. IP...
![[클로바 시선 #36] 토큰 한 알의 질주: LLM 서빙의 모든 것 (1)](https://blogthumb.pstatic.net/MjAyNTExMDdfNzEg/MDAxNzYyNTA0MTAzODky.ItK_tKVsRb3ZrUeb82BXvyd3jvdw_P26OIpT3R5-q7Ug.YMGJfKCNwV7M1WjlRIXBRMSU5ZmkoM0sfrjvxiWSdgUg.PNG/250926_%BC%F6%B4%C9%B9%AE%C1%A6.png?type=s3)
LLM은 어떻게 화면에 ‘첫 글자’를 띄울까? 요즘 가장 뜨거운 기술 키워드를 꼽자면 단연 LLM(Large Language Model)입니다. 질문에 술술 답하고, 소설도 쓰고, 코드까지 짜는 모델의 활약은 하루가 멀다 하고 화제가 되죠. 하지만 화려한 인터페이스 뒤편에 실제로 어떤 일이 벌어지고 있는지, 생각해 본 적 있으신가요? 사용자가 채팅창에...

[11월 첫째주] 알약 스미싱 알림 본 포스트는 알약M 사용자 분들이 '신고하기' 기능을 통해 알약으로 신고해 주신 스미싱 내역 중 '특이 문자'를 자체&nb...
AWS에 자주 접수되는 질문 중에 이런 것이 있습니다. “다양한 리전에서 사용할 수 있는 AWS 기능은 각각 무엇인가요?” 리전 확장을 계획 중이거나, 데이터 레지던시 요구 사항 규정 준수를 보장하려 하거나, 재해 복구를 위한 설계 중이라면 참 중요한 질문입니다. 그런 의미에서 AWS Capabilities by Region을 소개하게 되어 기쁩니다....

JetBrains AI Meetup Seoul 2025에서는 AI 시대를 함께 맞이하는 개발자와 기업이 어떻게 고민하고, 어떤 방향으로 성장할 수 있을지에 대한 인사이트를 나누는 시간을 준비했습니다. AI 에이전트 활용부터 멀티 에이전트 협업, 원격 AI 실행까지, JetBrains가 제시하는 IDE에서 AI 도구로 확장되는 새로운 개발 경험을 직접 ...

비즈니스와 사용자 경험, 두 가지를 모두 챙기려면 어떻게 해야할까요? 둘 사이 교집합을 찾아낸 과정을 알려드릴게요.

주요소식 다음과 같은 유용한 정보들을 만나보실 수 있습니다. 1. React Conf 2025 - React의 대규모 업데이트 React 19.2에서 컴포넌트와 useEffectEvent() 훅을 도입하고 React Compiler 1.0을 정식 출시하여 자동 최적화를 제공합니다. 특히 Meta Quest 스토어 앱에서 로드 시간 12% 개선과 2배 ...
![[이벤트] 이스트시큐리티 신규 고객 대상 2025 연말 특별 프로모션!](https://blog.kakaocdn.net/dn/bTp5Gq/dJMb99LsG75/aakFRDLpkERbH6ehfXk0H0/img.jpg)
by 이스트시큐리티 마케팅팀 안녕하세요, 이스트시큐리티입니다. 2025년 연말을 맞아, 기업 필수 보안 솔루션 도입과 역대급 프리미엄 사은품 혜택을 동시에 누릴 수 있는 '신규 고객 특별 프로모션'을 11월부터 12월까지 1개월동안 한정 기간 진행합니다. 이번 기회에 비즈니스 보안 환경을 업그레이드하고...

📖 목차 개요 모듈 페더레이션(Module Federation - MF) 넌 뭐니? MF의 특징은 뭐가 있을까? MF의 구현 방법은? MF…
![[클로바 스튜디오 Cookbook] RAG의 활용도를 높일 수 있는 Neo4j 기반 GraphRAG Cookbook](https://blogthumb.pstatic.net/MjAyNTExMDVfMTk5/MDAxNzYyMzMzNTg1NzIx.L0RFW7qKk2FZlGOENi-XBkoyaHjLal7BSJ_zod7zAKAg.CL17CqshZa5iW7BbwKXH8_G-xDnxRRev62Hh-BCDUqcg.PNG/thumbnail_graphRAG.png?type=s3)
️ GraphRAG는 데이터 간의 관계를 이해하고, 그 맥락 속에서 답을 찾아갑니다. 기존 RAG가 문서 단위의 검색에 머물렀다면, GraphRAG는 지식 그래프를 활용해 정보를 연결된 형태로 이해합니다. Neo4j 기반 GraphRAG는 문서 속 정보를 구조화하고, 데이터 간 관계를 해석해 더 정확하고 근거 있는 답변을 생성하도록 돕습니다. 들어가며...

안녕하세요! 올리브영의 iOS Junior Engineer Ted입니다. 저는 오늘, 올리브영 iOS…

YouTrack 2025.3 버전에서는 원격 모델 컨텍스트 프로토콜(MCP)에 대한 지원이 추가되어 개발자가 YouTrack으로 통합 도구를 구축할 수 있는 길이 넓어졌습니다. 이 프로토콜을 이용하면 AI 기반 도구를 YouTrack에 안전하게 연결하여 LLM, IDE 또는 에이전트 플랫폼에서 바로 작업을 관리할 수 있습니다. 또한 JetBrains ...
![[네이버클라우드 아카데미] 건양대학교 네이버클라우드 아카데미 홍보 서포터즈 CLOVER 1기 활동을 마치며](https://blogthumb.pstatic.net/MjAyNTExMDVfODUg/MDAxNzYyMzA5NTA4MjY2.jfDMfDUdexdFnBeZFxwy3JDniKrE6nfpn2JXLtP0EFYg.wJW_8n9y9twq2w5rIKGpfW3EPusoZ3EqcIVgUZJlolgg.PNG/251103_%B0%C7%BE%E7%B4%EB%BE%C6%C4%AB%B5%A5%B9%CC.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드(ncloud.com)입니다. #네이버클라우드 #네이버클라우드아카데미 #건양대학교 #CLOVER #1기 #홍보서포터즈 안녕하세요, 여러분! 오늘 전해드릴 반가운 소식은 건양대학교 네이버클라우드 아카데미 홍보 서포터즈 'CLOVER'의 빛나는 활동 소식인데요! CLOVER는 건양대학교 학생들이 직접...
마일리지, 도토리에서 시작된 디지털 가치 교환의 역사를 거슬러 올라가 암호화폐 기반 결제 및 송금 서비스의 등장 배경과 현재 상황을 심층적으로 분석합니다.
![[로켓펀치 소식] KBW 2025의 열기 속으로, 로켓펀치가 다녀온 Nodit Pocha 현장](https://play-lh.googleusercontent.com/w1My0dMHSuoFcU0EYE-oDUDf9xwSCX7QAHAKR4TAomvZskr7CGfSng6mzuQ0Vmv5yiQ=w240-h480-rw)
KBW 2025 현장 속 가장 뜨거운 네트워킹 자리, Nodit Pocha에 로켓펀치가 함께했습니다. 블록체인 업계의 다양한 사람들과 만남을 나누고, 로켓펀치가 선보이는 블록체인 기반 커리어 네트워킹 플랫폼을 직접 소개했어요. 그날의 생생한 현장 분위기를 전해드립니다, 🌐 KBW와 Nodit Pocha, 어떤 행사였을까? ‘KBW(Korea Block...