토스
토스의 브랜드 심볼을 찾아서
Else
인사이트 수준에 머물기 쉬운 추상적인 브랜드 리서치를 실제로 적용한 방법을 알려드려요.
2025-12-01
국내 IT 기업들의 기술 블로그 글을 한 곳에서 모아보세요

인사이트 수준에 머물기 쉬운 추상적인 브랜드 리서치를 실제로 적용한 방법을 알려드려요.
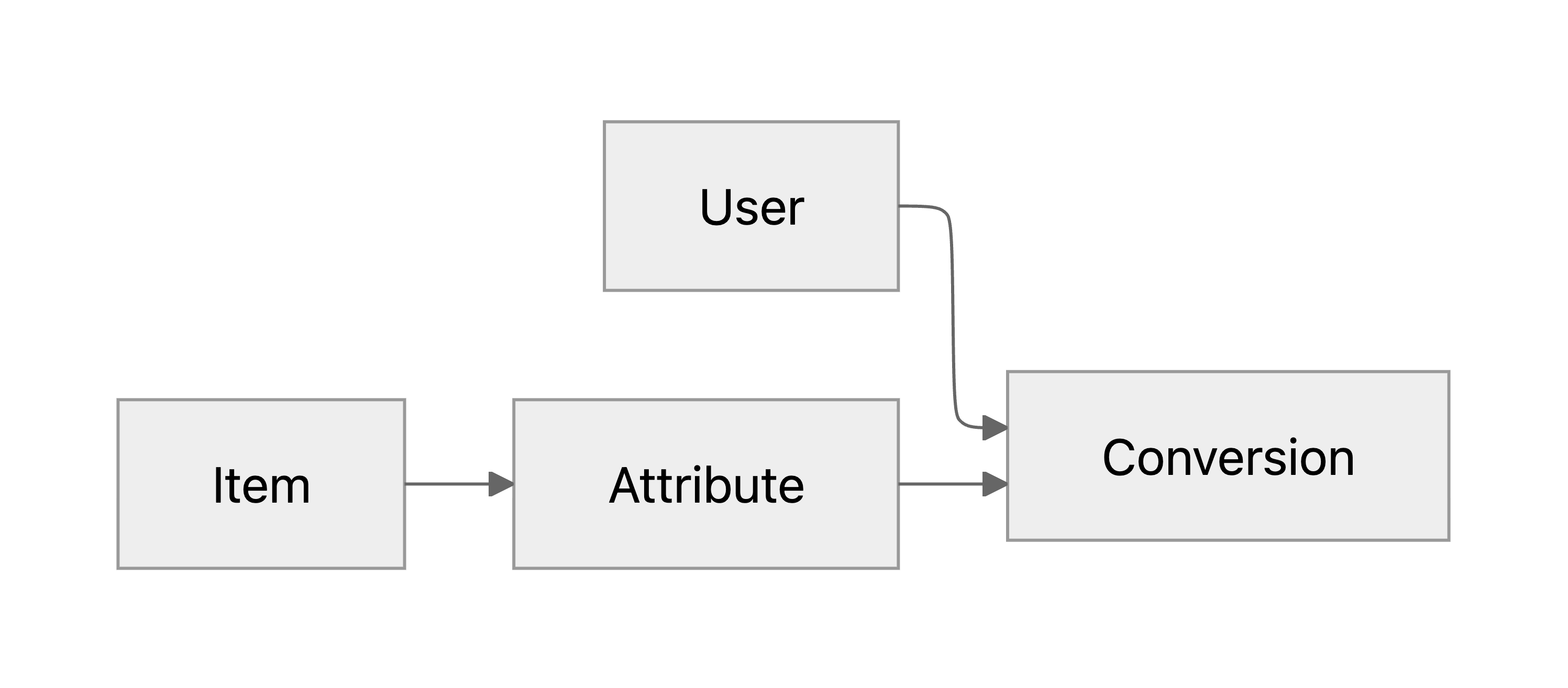
실제 비즈니스 목표를 최적화하기 위해 머신러닝 모델의 타겟 메트릭을 정하는 방법을 소개합니다.
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 네이버 통합 검색에서 더 나은 장애 대응 프로세스를 위해 LLM Agent를 활용하는 방식에 대해 소개합니다. Agent 를 어떤 방식으로 구성하고 구축했는지, 어떻게 평가하고 활용하고 있는지를 자세히 소개합니다. 발표 ...

AI가 인터뷰까지 대신하는 시대, 리서처는 어디에 집중해야 할까요? 변화 속 UX리서처의 진짜 역할을 이야기해보려 해요.

들어가는 글 우아한형제들의 수많은 시스템에서 남는 로그는 매우 방대한 양을 자랑합니다. 운영환경 기준으로 하루 수십TB의 데이터가 처리되고 있고, 피크타임 기준으로 초당 레코드 수는 100만 단위를 가뿐히 넘기고 있습니다. 이렇게 데이터가 많은 것만으로도 버거운데, 한 술 더 떠서 우아한형제들 서비스 트래픽은 극심한 변동성을 자랑합니다. 사용자의 요청...

Hello! I’m peter.kim, a backend engineer on the Daangn Pay Compliance & Strategy team.Our team builds and operates financial compliance systems — including FDS and AML — to ensure that Daangn P...

웹 애플리케이션을 개발하다 보면 하나의 HTTP 요청 내에서 동일한 외부 API를 여러 번 호출하거나 동일한 연산을 반복하는 경우가 종종 발생합니다. 이러한 중복 호출은 응답 시간을 증가시키고 불필요한 네트워크 오버헤드를 유발합니다. 이 글에서는 이러한 문제를 해결하기 위해 개발한 @RequestCache라는 커스텀 애너테이션의 개발 과정과 그 과정에...
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 로컬 환경에서 Ollama LLM과 mcp-agent를 연결해 빌드 실패 분석, 크래시 로그 요약, Slack 자동 리포트까지 구현했습니다. AI가 단순한 도구가 아닌, 프로젝트의 자동화 동료가 되는 과정을 공유합니다. ...

K-콘텐츠 저작권 보호 및 창작 생태계 발전에 기여한 공로 인정 The post 리디, ‘제2회 대한민국 저작권 보호 대상’ 문화체육관광부 장관표창 수상 appeared first on 리디주식회사 RIDI Corporation.

팀 내에서 범용 개인화 추천 시스템을 구축하며 온라인 A/B 테스트와 CRM 캠페인 테스트에서 비교적 좋은 성과를 확인해, 그 개선 사례와 모델링 과정을 소개하고자 합니다.
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 네이버 통합검색의 클릭 로그를 히트맵과 히스토그램으로 시각화하여 직관적으로 사용자 행동을 파악할 수 있는 기술을 소개합니다. 실시간으로 진화하는 네이버 검색 서비스를 대응하기 위해 겪은 시행착오와 노하우를 공유합니다. 발...

전자계약서 시스템에서는 다양한 업무 목적에 따라 여러 형태의 대용량 엑셀 파일을 생성할 수 있습니다. 예를 들어 생산성 지표 엑셀, 근무 관리 엑셀, 행정 처분 추정 업주 엑셀, 계약현황 엑셀 등 각기 다른 조건과 데이터로 구성된 엑셀을 이메일로 받아볼 수 있는 기능인데요. 데이터 조건에 따라 엑셀 생성 시간이 오래 걸려, 화면에서 결과를 기다리지 않...
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 과거 데이터 파이프라인의 문제를 해결하고 사용자 중심의 on-demand data lineage pipeline 서비스인 Flow.er를 개발하고 발전시킨 내용에 대해 소개합니다 DBT, Airflow를 활용하여 어떻게 ...

안녕하세요. 당근페이 Compliance & Strategy 팀에서 백엔드 엔지니어로 일하고 있는 peter.kim이에요.저희 팀은 FDS, AML 등을 포함한 금융 컴플라이언스 시스템을 만들고 운영하면서, 당근페이가 안전하게 서비스될 수 있도록 하는 역할을 하고 있어요. 쉽게 말하면, 사용자의 거래에서 이상 패턴을 감지하고, 법과 규제를 준수...

작품 전체에서 가장 큰 전환점이 되는 시즌으로 원작 핵심 메시지 표현 The post 리디, 글로벌 인기 웹툰 ‘상수리나무 아래’ 시즌5 공개 appeared first on 리디주식회사 RIDI Corporation.
![[웹툰 파헤치기] 역대급 작화가 온다…‘악인 남편’](https://static.teamblind.com/img/cppc/upload_5ab60103.jpeg)
The post [웹툰 파헤치기] 역대급 작화가 온다…‘악인 남편’ appeared first on 리디주식회사 RIDI Corporation.
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 Consumer Group Protocol v2를 소개합니다. 발표 대상 조직에서 Kafka를 사용하거나 관심 있는 분들 Consumer Group Protocol 에 대해 관심 있는 분들 목차 Consumer Group...
.png)
토스가 자체 개발한 지표 MTVi를 통해 플랫폼 관점에서 데이터를 분석하고 활용하는 방법을 소개합니다.
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 API 호출식 웜업의 부작용을 개선한 라이브러리 웜업을 소개합니다. 발표 대상 JVM JIT Compiler의 웜업 방식 기본을 알고 있는 분 또는 관심있는 분 JVM 기반 웹 어플리케이션의 웜업에 관심있는 분 목차 JV...
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 검색 모니터링 플랫폼인 SEER를 OpenTelemetry, OpenSource 기반으로 전환을 준비하며 OpenTelemetry에 대해 학습한 내용과, OpenTelemetry 생태계에 기여한 경험을 공유합니다. 목차 ...
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 Telegraf를 활용한 Exporter 개발 경험 공유 및 가이드를 소개합니다. 발표 대상 오픈소스 기반 Exporter와 Telegraf 적용을 고려중인 엔지니어 목차 오픈소스 기반 Exporter 도입 배경 오픈소스...

네이버페이 차세대 아키텍처 개편을 위한 Plasma 프로젝트가 7년의 기간 끝에 2025년 7월부로 공식 종료를 선언했습니다. 이 글에서는 Plasma 프로젝트의 최종장인 DB CDC 복제 도구 ergate 프로젝트의 개발 및 전환 경험을 공유하고자 합니다. ergate 프로젝트 소개 ergate 프로젝트는 네이버페이 주문에서 DB 간 복제를 수행하는...

콘텐츠 저작권 침해 범죄에 대한 사법적 기준 명확히 제시 The post 웹툰불법유통대응협의체, 불법 웹툰 사이트 운영자 중형 선고 항소심 판결 환영 appeared first on 리디주식회사 RIDI Corporation.
'백엔드 개발자를 꿈꾸는 학생개발자'에게 후속편이 7년만에 돌아옵니다! NAVER D2 블로그를 보고 계신 분들이라면 한번쯤은 '백엔드 개발자를 꿈꾸는 학생개발자에게' 라는 글을 본적이 있으실텐데요, 무려 작성된 지 7년이 지났지만 지금도 꾸준히 TOP 5에 드는 D2 블로그의 대표 글 중 하나입니다. 이 글을 작성해주셨던 NAVER 정상혁 님께서 그...

SDK를 개발하며 마주한 다양한 상황과 기술적 어려움, 그리고 이를 해결하기 위해 우리가 설정한 핵심 가치와 달성해온 과정을 공유합니다.
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 Large Screen을 대응해야 하는 이유와 품질 가이드라인을 소개합니다. 글로벌웹툰이 View와 Compose 환경에서 Large Screen 최적화를 적용한 내용을 일부 공유합니다. 발표 대상 Large Screen...
네이버 사내 기술 교류 행사인 NAVER ENGINEERING DAY 2025(10월)에서 발표되었던 세션을 공개합니다. 발표 내용 Actions Runner Controller 를 사용하여 Kubernetes 클러스터 위에서 GPU 서비스 개발을 위한 CICD 인프라를 확장 가능한 형태로 구축하는 방법을 소개합니다. 발표 대상 Github Actio...
![[클로바 스튜디오 Cookbook] (1부) MCP 실전 쿡북: LangChain에서 네이버 검색 도구 연결하기](https://blogthumb.pstatic.net/MjAyNTExMTFfMTkg/MDAxNzYyODQzMjc1NDA4.YSW1oiL_J6NCSmYoxueQE27DrY1zM9mHTQSUJcHmD2Qg.SZu0slkszIME_Z6b3j9zpbb25Ud-2My5uIIKwxl9OX0g.PNG/thumbnail_MCP_%BD%C7%C0%FC_%C4%EE%BA%CF_1%BA%CE.png?type=s3)
AI가 도구를 직접 부르고, 데이터를 자유롭게 다루는 방식. 그 중심에는 MCP가 있습니다. 이번 MCP 실전 쿡북 시리즈는 총 4부작으로, LangChain 연동부터 세션 관리, OAuth 인증, 운영 팁까지 MCP를 제대로 활용하는 실전 노하우를 단계별로 담았습니다. 그 첫걸음인 이번 1부에서는 LangChain 환경에서 네이버 검색 API를 연결...
![[CSAP 고객사 사례집 #1] 크리니티가 전해주는 공공 SaaS 도전기 1편 - 인증 준비부터 3가지 챌린지까지](https://blogthumb.pstatic.net/MjAyNTExMTNfMjg5/MDAxNzYyOTk4MTY4MTkx.IlAeztU2ZdsGXSxlS9gd-Kjb126uJS_VxGpVyZ9eClMg.nhTQ0kV4EYkG2ax2VSTT8YcdvnlYu2Cf6O8jDR8pHpwg.PNG/2511104_%BD%E6%B3%BB%C0%CF.png?type=s3)
안녕하세요. 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com 입니다. 메일 보안 전문 기업인 크리니티는 27년 이상의 노하우를 바탕으로 메시징 분야 솔루션 개발부터 서비스 운용까지 일괄 제공하는 보안 메일 서비스 전문 기업입니다. 문화체육관광부, 경찰청, 조달청 등 다수의 공공기관이 정보보안 적합성 수준에 맞는 행정메일시스템을 구축할 ...

Backoffice AI Agent 구축기 — RAG+MCP 기반 플레이스AI 특화 지식 검색 시스템주제: 사내 백오피스 Agentic RAG 시스템 개발키워드: RAG, MCP, Semantic Search, Hybrid Retrieval, RRF, LLM Reranker, Milvus, OpenSearch, Agentic Knowledge Sear...