삼성 SDS
망 중립성: 기업 네트워크와 비즈니스 전략에 미치는 영향
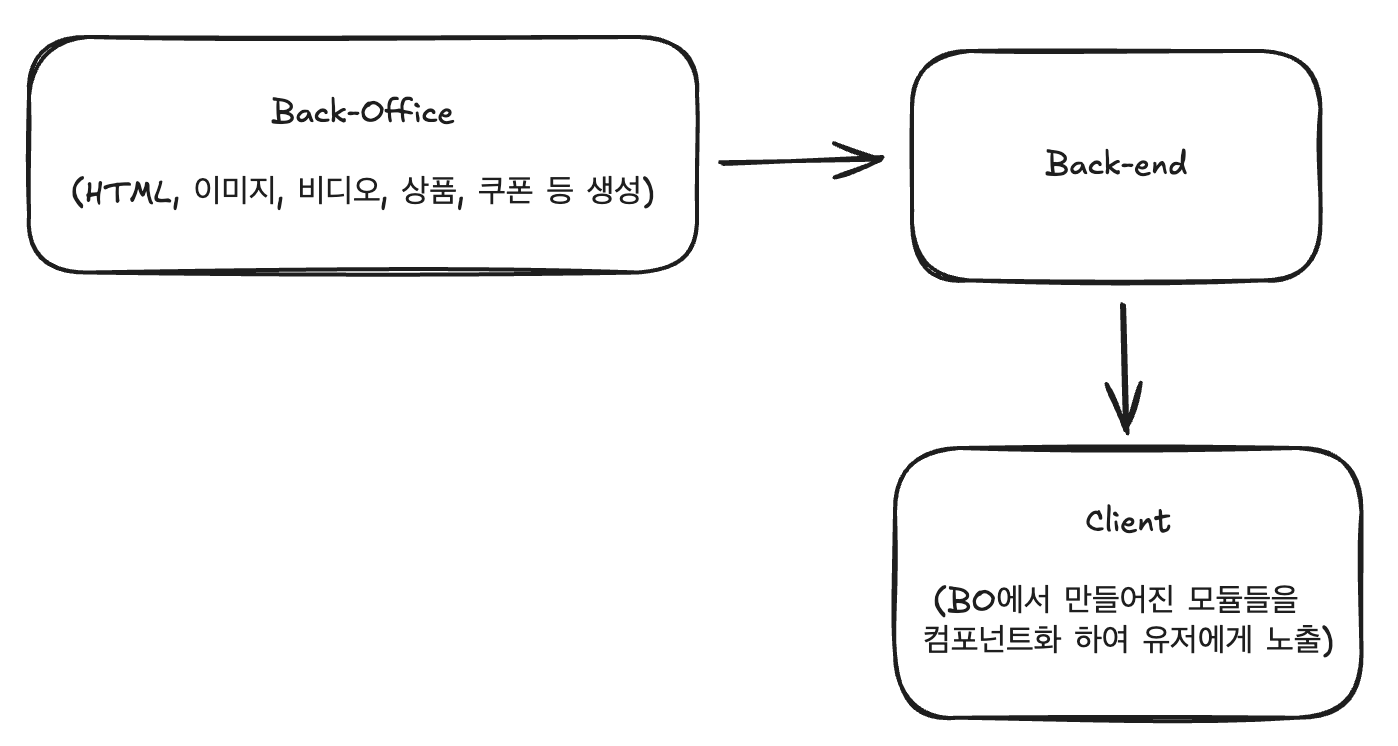
아키텍처
이 글은 망 중립성(Net Neutrality) 정책이 기업 네트워크와 인터넷 서비스에 미치는 영향에 대해 심도 있게 분석하고 있습니다.
2024-11-04
국내 IT 기업들의 기술 블로그 글을 한 곳에서 모아보세요
이 글은 망 중립성(Net Neutrality) 정책이 기업 네트워크와 인터넷 서비스에 미치는 영향에 대해 심도 있게 분석하고 있습니다.
안녕하세요. 질문을 사랑하는 올리브영 프론트엔드 개발자 “우문Hyun답”입니다.😁 스토어전시 스쿼드에서는 24년 2-3분기에 기존 JSP로 구현된 기획전 시스템을 Next.js…
안녕하세요. 저는 LINE+ ABC Studio에서 앱을 개발하고 있는 윤기영입니다. 최근 운영 중이던 앱의 규모가 점점 커지면서 기존 구조로는 앱을 유지 보수하거나 확장하기 어려...

쿠키런: 킹덤 서버 개발자와 함께 읽어보는 『스칼라로 배우는 함수형 프로그래밍』
이번 아티클에서는 업무 효율성을 향상하고, 창의적 가치를 창출하는 데 중요한 역할을 하는 생성형 AI와 하이퍼오토메이션을 중심으로 '일의 플라이휠'을 살펴보고자 합니다.
…
이 글은 LINE Engineering Blog에 발행했던 글을 LY Tech Blog로 재발행하였습니다. 서비스 소개 '데마에칸(出前館)'은 2000년부터 서비스를 시작...
이 아티클에서는 클라우드의 어두운 단면에 대해 살펴봅니다. 퍼블릭 클라우드 사용 기업의 74%가 공개적으로 노출된 스토리지나 잘못된 설정을 갖추고 있다고 합니다.

이미지 출처 -링크프로젝트를 진행하며 데이터 분석가나 PO로부터 A/B 테스트를 진행한다는 얘기를 한 번쯤은 들어보셨을 것입니다. A/B 테스트는 업무에서 자주 언급되는 개념으로, 많은 기획서와 성과 분석에서 그 필요성이 강조됩니다.이 글에서는 A/B 테스트의 정의와 효과적인 진행을 위해 필요한 조건들을 다루고자 합니다. 이를 통해 보다 효율적인 의사...
들어가며 안녕하세요. LINE NEXT DevOps 팀에서 쿠버네티스 운영 및 유지 보수, CI/CD 구축, 모니터링, 로그 수집 등 인프라 전반에 걸쳐 업무를 수행하고 있는 이동...
MZ 세대를 중심으로 조각투자가 인기를 끌면서 토큰증권의 수요가 증가하고 있습니다. 이 아티클에서는 금융자산을 디지털 토큰으로 변환시키는 '토큰증권'의 개념과 디지털 자산 시장에 대해 알아봅니다.

컬리의 새로운 배송 시스템 구축 과정과 프로젝트에서 얻은 교훈을 소개합니다.
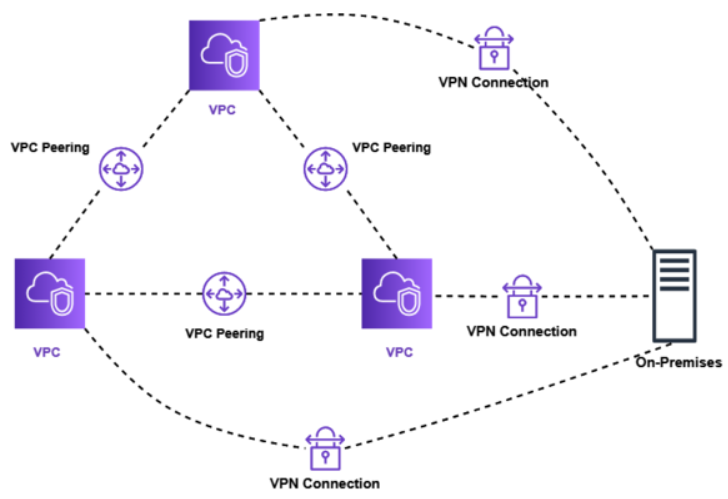
# GS SHOP의 AWS 네트워크 변경 배경 GS SHOP은 오랜 기간 운영해온 인천 IDC의 서비스 종료에 맞춰, All Cloud 전환을 목표로 1,000대 이상의 서버를 클라우드로 이전하기 시작했습니다. 이 대규모 전환 작업은 2024년 성공적으로 마침표를 찍게 되었고, 이 과정에서 고도화 및 개선한 경험을 나눠보고자 합니다. # ...
Zip Bomb 에러 소개 및 해결 방법 공유
이 글에서는 AI 도구들의 문제점과 이를 보완하는 새로운 AI 도구들의 등장에 대해 살펴보고, 이러한 기술이 업무 생산성을 높이는 데 어떻게 사용되는지 소개합니다.
안녕하세요. 일본 최대 규모의 음식 배달 서비스 Demaecan(出前館, 이하 데마에칸) 프로덕트를 담당하는 김영재라고 합니다. 어느덧 프로덕트를 쇄신한 지 2년 반이 되어가고 있...

GS리테일에서 비즈니스 데이터 분석을 담당하고 있는 임현정 매니저님을 만나 이야기를 나누어 보았습니다. 안녕하세요, 매니저님! 근무하고 계시는 팀과 자기 소개 부탁드립니다. 안녕하세요, 저는 DX본부의 플랫폼데이터분석팀에서 데이터 분석가로 일하고 있는 임현정 매니저입니다. 플랫폼데이터분석팀은 GS리테일의 편의점과 수퍼...
이 아티클에서는 생성형 AI가 소프트웨어 개발 분야에 미치는 영향에 대한 분석과 전망을 담았습니다. 향후 AI 에이전트가 대부분의 코드를 작성하고 숙련된 개발자가 이를 검토하는 새로운 소프트웨어 개발 시대가 도래할 것으로 보입니다.

 # 들어가며 이번 글에서는 멀티 테넌트 서비스에서 테넌트 데이터 격리 방법과 격리 수준을 높일 수 있는 몇 가지 방법에 대해 알아봅니다. # 1. 테넌트 데이터 격리 **테넌트(tenant)**는 하나의 플...
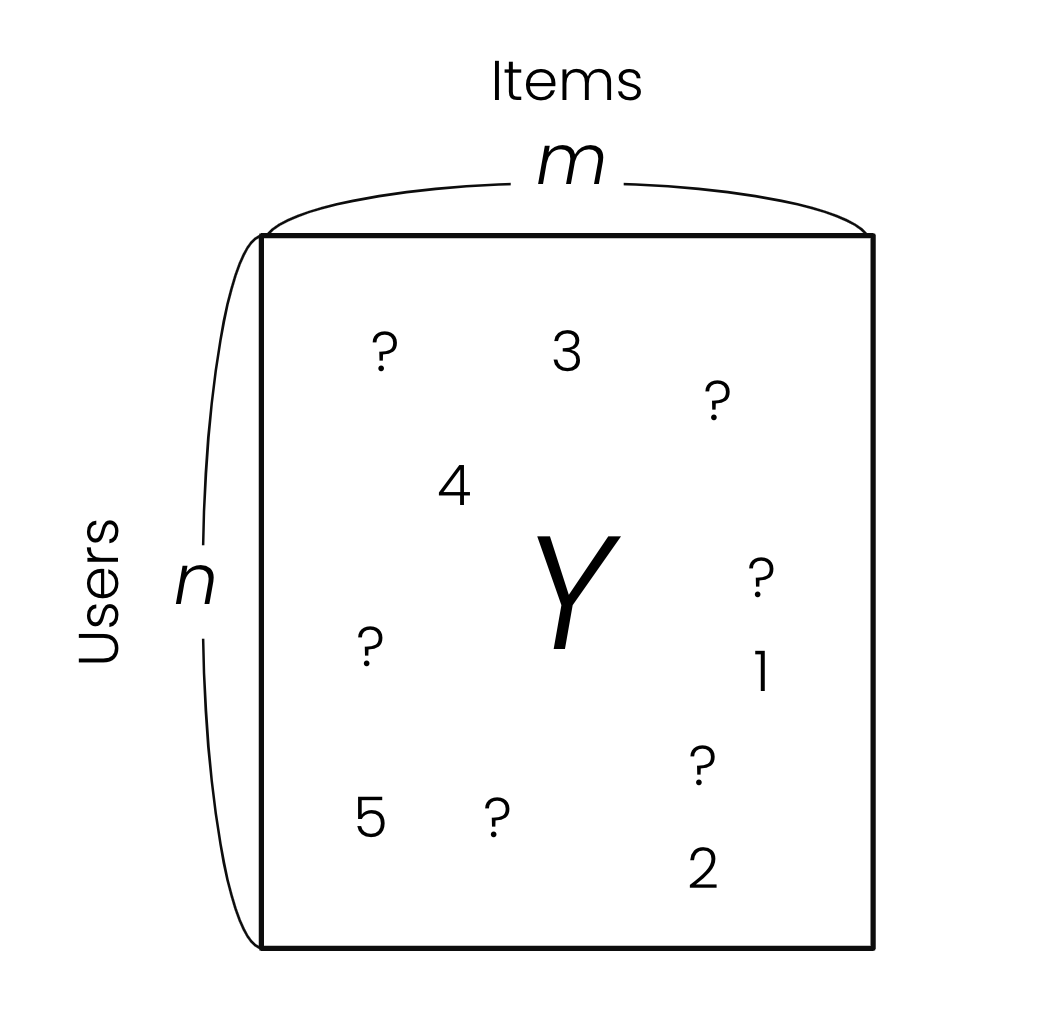
지난 포스트에서 살펴본 것처럼 추천 시스템은 하이퍼커넥트 비즈니스에서 중요한 역할을 하고 있습니다. 하이퍼커넥트는 50개 이상의 모델을 프로덕션 환경에서 운영 중이며, 그중 다수가 추천 시스템에 활용되고 있습니다. 이번 포스트에서는 하이퍼커넥트 AI 조직이 다양한 추천 엔진에서 어떤 모델링 기법을 적용하고 있는지 소개하고자 합니다1. 협업 필터링(co...

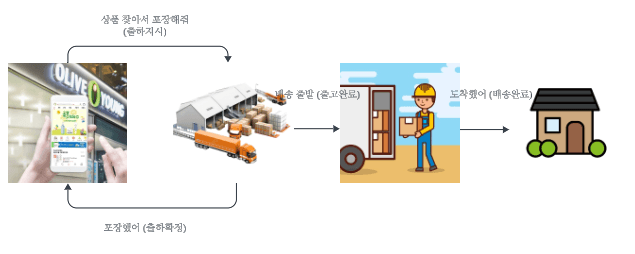
…
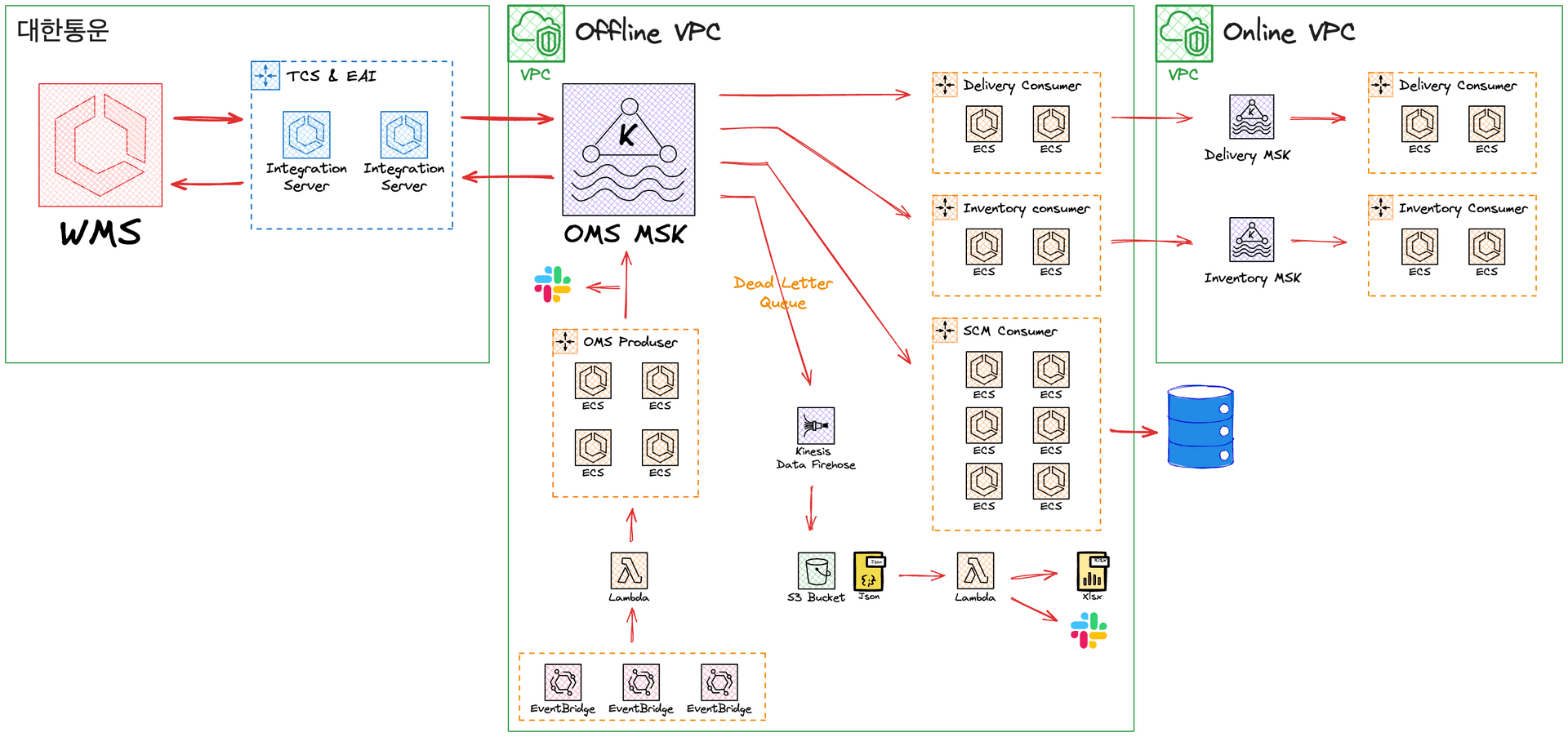
안녕하세요. 풀필먼트 스쿼드에서 백엔드 개발을 담당하고 있는 시나브로우입니다. 저는 최근 공급망 관리(Supply Chain Management)를 통해 올리브영의 비즈니스 목표를 극대화하는 SCM 스쿼드에서 이적하였는데요. 이적 전인 2024년…
이 아티클의 핵심주제는 AI 에이전트로, 이는 사용자들의 업무 특성을 파악하여 맞춤형으로 서비스를 제공하며, 기업의 전반적인 효율성과 경쟁력을 끌어올릴 것으로 전망합니다.
스프링부트 버전을 업그레이드하는 과정에서 발견된 버그 해결기
생성형 AI 시대에서 성공하려면 데이터 사이언티스트는 그들의 접근 방식을 재고해야 합니다. 포괄적이고 효율적인 작업을 수행하는 방법을 배우기 위해 비정형 데이터 소스를 통합하고, AI 윤리를 실행하고, 새로운 도구를 활용하는 등 필수 영역에 초점을 맞추어야 합니다.
이번 아티클은 2024년 9월, 삼성SDS가 대외 고객을 대상으로 진행한 「REAL SUMMIT 2024」 행사 중, ‘Hyperautomation 추진을 위한 고려 사항 5가지’ 세션 발표 내용을 기반으로 작성되었습니다.

목차0. 들어가며 0.1 데이터 활용을 위해 필수불가결한 배치 시스템1. 기존 데이터 활용 배치 시스템의 문제점 1.1 Zeppelin Cron 기능을 이용한 배치 1.2 Airflow기반 파이프라인 생성 배치 1.3 Redash를 통해 주기적으로 대시보드생성2. 새로운 데이터 활용 배치 시스템 2.1 요구사항 및 설계 2.2 아키텍처 3. FAST의 주요기능 3.1 배치 조회 3.2 배치 생성 3.3 이외의 기능4. 도입 후: 기존 프로세스 vs FAST 활용 프로세스 4.1 AS-IS: 기존 프로세스 4.2 TO-BE: FAST 활용 프로세스5. 맺으며안녕하세요, 네이버페이 인텔리전스플랫폼팀 신태범입니다.0. 들어가며저희 팀은 데이터 엔지니어링 팀으로, 조직 내에서 데이터가 성공적으로 활용될 수 있도록 여러 업무를 수행하고 있습니다. 이를 구체적으로 살펴보면, 데이터 인프라 운영과 관리, 네이버페이 서비스에서 생성되는 데이터의 수집, 그리고 데이터 거버넌스를 포함합니다.팀에서 담당중인 업무들데이터 문화가 고도화됨에 따라, 데이터팀이 해야 할 역할은 더욱 다양해지고 있습니다. 그 중 하나는 서비스 담당자들이 최소한의 개발 지식으로도 도메인 지식을 활용해 데이터를 쉽게 다룰 수 있도록 지원하는 것입니다.개인이나 조직이 데이터를 효과적으로 이해하고 활용할 수 있도록 하는 시스템을 ‘데이터 리터러시 플랫폼’이라고 부릅니다. 사용자들이 필요로 하는 데이터 리터러시 도구들을 지속적으로 개선하고 개발하는 것은 조직의 데이터 리터러시를 높이는 중요한 방법 중 하나입니다.이 글에서는 저희 팀의 데이터 리터러시 플랫폼 중 웹기반 데이터 파이프라인 생성 툴인 FAST에 대해 소개하고자 합니다. FAST는 FDC automated self tasker의 약자로 빠르게 배치를 구성할 수 있다는 의미를 담고있습니다. 기능적으로는 웹기반으로 사용자 입력을 받아 Airflow DAG 생성을 자동으로 연계해주는 툴입니다.이 글이 정형화된 파이프라인 템플릿을 보유하고 있거나, 파이프라인을 전사적으로 효과적으로 활용할 방법을 찾고 계신 분들께 도움이 되길 바랍니다. 또한, 파이프라인이 없더라도 조직 내 데이터 리터러시를 향상시키기 위해 고민하는 분들께 유용한 참고자료가 되었으면 좋겠습니다.0.1 데이터 활용을 위해 필수불가결한 배치 시스템### S님의 업무일지처음에는 필요한 데이터를 얻기 위해 제플린 같은 도구를 사용해 직접 찾아보는 단계에서 시작했습니다.하지만 시간이 흐르면서, 매일매일 같은 종류의 데이터를 볼 필요성이 생기기 시작했죠.그래서 우리 팀에선 그런 데이터를 쉽게 볼 수 있게 '마트 테이블'이라는 것을 만들기 시작했습니다. 그리고 일별, 주별, 월별로 데이터를 살펴보고 이상치가 없는지 확인하며, 중요한 부분들을 눈에 띄게 '시각화'하는 걸 배웠습니다.이건 Redash라는 것을 사용해서 가능했죠.그리고 이런 정보들이 필요하다고 생각되는 팀원들에게나, 전사적으로 중요한 KPI와 관련 있는 정보들은 함께 공유하기 시작했습니다.처음엔 데이터를 보기 위한 SQL 쿼리를 작성하는 것이 어려웠지만, 점차 익숙해지더군요.그리고 그 다음 단계로, 데이터를 뽑고 분석하는 과정을 '자동화'하는 방법을 배우게 되었습니다.이에 '배치 시스템'이라는 것을 활용하게 되었죠.이렇게 하면 데이터 처리 과정을 편하게 자동으로 돌릴 수 있어 시간을 절약하여 업무 효율을 높일 수 있었습니다.데이터 기반 의사결정 조직에서 사용자들은 어떻게 데이터 문화에 익숙해져갈까요? 처음에는 SQL을 직접 사용하거나 팀에서 공유받은 쿼리 템플릿을 활용하여 필요할 때마다 제플린 등의 데이터 분석 노트북 툴로 단순히 데이터를 조회합니다.일시적인 쿼리뿐 아니라, 의사결정을 위해 주기적으로 데이터를 추출해야 하는 경우도 있습니다. 이러한 작업이 반복되면 자주 사용하는 테이블을 JOIN하여 다른 구성원들이 쉽게 활용할 수 있도록 미리 마트 테이블을 생성하게 됩니다.사용자들은 이렇게 생성한 마트 테이블을 활용해 일별, 주별, 월별 등으로 이상치와 집계 결과를 정기적으로 확인합니다. 또한, BI 도구로 보다 직관적으로 결과를 시각화하고, 필요한 경우 팀원들과 공유하며 의사결정을 진행할 수 있습니다. 더 나아가 조직의 중요한 KPI와 관련된 경우 전사에 공유하는 자료에도 이를 활용할 수 있습니다.이 과정을 반복하게 되면 사용자들은 쿼리에 빠르게 익숙해지고 능숙하게 데이터를 볼 수 있게 됩니다. 사용자는 계속해서 반복되는 데이터 추출 관련 업무에 쏟는 시간을 최소화하고 효율적으로 일하기 위해 자동화 배치 시스템을 사용하고자합니다.실제 데이터 활용 시나리오1. 기존 데이터 활용 배치 시스템의 문제점위에서 설명한 흐름에 따라 점차 구성원들이 데이터 보는 법을 알게 되고, 사내에 데이터 문화가 자리 잡아갑니다. 네이버 페이 역시 구성원들의 데이터 리터러시가 향상되며 배치 시스템의 니즈는 커졌습니다.이에 따라 저희 팀에서도 사용자들의 니즈에 맞춰 다양한 배치 시스템을 지원 했습니다. 크게 아래 네가지로 나누어집니다.1. Zeppelin상에서 작성한 집계쿼리의 결과를 주기적으로 메일로 받아보고 싶어요- Zeppelin Cron2. 여러 서비스 시스템 간의 수치가 맞는지 맞춰보고 싶어요(시스템 간 대사)- 데이터 엔지니어가 직접 Airflow DAG로 배치 생성3. 좀 더 안정적인 배치를 통해 사용할 마트 테이블을 생성하고 싶어요- 서비스 실무자가 코드작성, 데이터 엔지니어 리뷰를 거쳐 Airflow DAG로 배치 생성4. 데이터를 활용해서 시각화하여 대시보드를 생성하고 싶어요- Redash를 통해 주기적으로 결과가 갱신되는 대시보드 작성그러나 시스템 도입 초기부터 앞으로의 모든 문제를 예측해 설계하는 것은 현실적으로 불가능합니다. 기존 프로세스 또한 당시의 사용자 니즈에 맞춰 도입되다 보니 시간이 지나며 다음과 같은 문제가 발생했습니다.1.1 Zeppelin Cron 기능을 이용한 배치Zeppelin CronZeppelin Cron은 노트북에 스케줄을 설정하여, 설정된 스케줄에 맞춰 노트북이 자동으로 실행되도록 하는 기능입니다. 제공되는 템플릿에 사용자가 결과를 보고 싶은 쿼리만 넣어주고, 스케줄만 지정하면 간단히 사용가능하다는 장점이 있었는데요. 하지만 이 방식에는 아래와 같은 문제점이 있었습니다.1.2 Airflow기반 파이프라인 생성 배치Airflow기반 파이프라인 생성 배치일부 데이터는 서비스와 밀접한 관련이 있기에, 안정적인 배치를 위해 내부 파이프라인 라이브러리를 통해 데이터를 추출 하기도 했습니다. 하지만 YAML, git, jenkins, github 등 비개발자에게는 낯선 지식이 필요하다는 허들이 존재했고, 수정이 필요할 때마다 데이터 엔지니어와의 커뮤니케이션이 필요하다는 문제점이 있었습니다.1.3 Redash를 통해 주기적으로 대시보드생성Redash 대시보드 화면숫자나 문자로 표현된 정보는 직관적이지 않습니다. 데이터를 한 눈에 시각화하고 인사이트를 효과적으로 전달할 수 있도록 Redash를 도입했습니다. 대시보드 내부의 데이터 배치는 Redash Scheduled Query 기능을 통해 주기적으로 갱신합니다.하지만 매번 필요할 때마다 Redash에 접속해야 한다는 불편함이 있어 주기적으로 대시보드를 메일로 받을 수 있는 기능에 대한 갈증이 존재했습니다. 또한 대시보드를 생성하기 위한 마트 테이블 생성을 위해 과도하게 무거운 쿼리가 실행되는 경우가 잦아 리소스 상의 문제가 발생하여 정상적으로 배치가 수행되지 않기도 했습니다.이외 문제점위에서 언급한 컴포넌트별 문제뿐만 아니라, 산발적으로 여러 컴포넌트에서 다양한 배치가 수행되고 있다보니 팀에서 관리할 포인트가 느는 등 유지보수 상에서도 불필요하게 공수를 잡아 먹는 문제가 있었습니다.2. 새로운 데이터 활용 배치 시스템위와 같은 사용자/관리자 입장에서의 불편함으로 인해서, 기존 데이터 활용 프로세스를 개선한 새로운 데이터 활용 배치 시스템이 필요했습니다.저희의 주된 사용자 분들 중에는 개발관련 지식에 친숙하지 않은 서비스 실무자 분들이 포함되어 있습니다. 그렇기에 누구나 쉽게 사용할 수 있도록, 웹기반으로 좀 더 직관적이고 접근성이 높은 툴을 개발하자는 결론을 내렸습니다.추가적으로, 개별 컴포넌트들의 문제 및 운영/관리 상의 문제와 추후 조직의 KPI를 취합하여 정리했을 때 아래 요구사항을 충족하는 툴을 만들고자 했습니다.2.1 요구사항 및 설계요구사항2.2 아키텍처FAST는 위에서 언급한 요구사항을 고려해서 다음과 같이 설계되었습니다FAST 아키텍처실제 배치는 안전성과 유지보수를 고려하여 workflow 툴인 Airflow를 사용Hive(JDBC), Bash, TextMailing, ScreenshotMailing, Join Task(Operator) 등을 쉽게 정의할 수 있게 웹에서 제공사용자는 필요한 Task를 추가하고, 각 Task의 필수 값을 입력만 하는 형태로 간단하게 안정적인 배치를 구성할 수 있음웹에서 구성한 데이터 파이프라인을 Python 코드와 YAML 구성 파일로 자동 변환한 후, 이를 Airflow로 배포하여 Airflow DAG으로 변환3. FAST의 주요기능앞서 소개드린 요구사항과 설계에 맞춰 새로운 데이터 활용 배치시스템을 개발하였습니다. 이 시스템은 빠르게 배치를 구성할 수 있다는 의미를 담아, FDC automated self tasker, FAST로 명명했습니다.웹 UI에서 정해진 필드를 단순히 채우기만 하면 배치를 생성할 수 있도록 개발하여, 그간의 데이터 파이프라인을 구성하기 위한 허들을 많이 낮추었고, 이를 통해 사용성은 높였습니다. FAST의 UI와 주요기능은 아래와 같습니다.3.1 배치 조회FAST Home3.2 배치 생성배치 생성 UI는 두개의 화면으로 나누어져 있습니다. 오른쪽에는 각 Task에서 필요한 인풋들을 입력받는 폼이 있습니다. 왼쪽에는 오른쪽에서 각 Task별로 설정한 디펜던시를 그래프를 보여줘 보다 직관적으로 실행흐름을 확인할 수 있도록 하고 있습니다.Task 설명ScreenshotMailing: 대시보드를 메일링하는 TaskTextMailing: 쿼리 결과를 메일링하는 TaskHive: hive 쿼리를 실행하는 TaskTask별 쿼리에 대해 쿼리검증 버튼을 누르면 실행전 오류를 미리 탐지3.3 이외의 기능이외에도 사용자 편의를 생각한 여러 기능을 제공 중입니다. 자주 사용되는 패턴은 템플릿으로 제공하며, 필요에 따라 이 템플릿을 복제해서 값만 대치하는 형태로 활용할 수 있도록 하고 있습니다. 또한 FAST는 git 커밋로그처럼 변경 메시지와 함께 변경 내역을 관리하고 있어서 과거 버전을 조회하거나 롤백할 수도 있습니다.다른 유저가 작성한 배치 복사배포 이력 확인배포 롤백배치 복제팀계정(키탭) 지원이외에도 사용자 요구사항을 지속적으로 반영하기 위해 사내 데이터 문의창구를 별도로 운영 중입니다. 무엇보다도, 사용자 편의성을 최고로 우선시하여 의견을 적극 반영하여 시스템을 개선해 나가고 있습니다.4. 도입 후: 기존 프로세스 vs FAST 활용 프로세스마지막으로, FAST 도입 전과 도입 후 사용자 입장에서 어떻게 데이터 파이프라인 작성 과정이 변경되었는지 살펴보도록 하겠습니다.AS-IS -> TO-BE4.1 AS-IS: 기존 프로세스기존 프로세스에서는 마트 생성을 위한 배치를 만들기 위해 사용자가 SQL 문법 이외에도 여러 개발지식을 익힐 필요가 있었습니다.사용자가 필요한 지식: git, 환경세팅, YAML, SQL, ndeploy(사내 배포툴)step1 개발환경을 세팅한다(git, vscode 등 설치)step2 YAML, git에 대한 지식을 쌓는다.step3 기존에 작성되어있던 예시를 보고 코드를 작성한다.step4 배포해본다. -> 왜안되지?step5 데이터 엔지니어에게 물어본다.step6 다시 수정한다. -> 배포해본다. -> 왜안되지? ...step7 어찌저찌 완성.. 하고 데이터 엔지니어에게 배포를 요청한다.step8 모니터링은 데이터 엔지니어가 해줌step9 원하는 결과가 나올때까지 반복4.2 TO-BE: FAST 활용 프로세스사용자는 기존에 학습한 SQL 문법과 간단한 FAST 사용법만 인지하면 쉽게 마트 테이블 생성 배치를 만들 수 있게 되었습니다.사용자가 필요한 지식: SQL, FAST 사용법step1 기존에 작성되어 있는 예시를 보고 input값을 적는다.step2 저장하고 배포한다.step3 원하는 결과가 나올때까지 반복5. 맺으며지금까지 개발지식이 필요했던 여러 배치시스템을 웹기반으로 통합한 FAST에 대해 소개드렸습니다. FAST 도입 이후, 사용자는 훨씬 적은 기반지식을 가지고 쉽게 배치를 생성할 수 있게 되었습니다. 또한 저희 팀에서는 커뮤니케이션 및 산발적인 컴포넌트를 관리를 위한 공수가 줄어들어, 인프라 고도화 및 다른 업무에 집중할 수 있게 되었습니다.추후 개발FAST의 성공적인 안착 이후, 현재 비개발자 분들의 손쉬운 모델 개발을 위한 AutoML 및 사용성을 높이기 위한 python, Spark 실행을 지원하는 Pyspark 등을 도입하기위해 내년 상반기들 목표로 인텔리전스서비스팀과 협업하여, 개발중에 있습니다.이를 통해 FAST는 데이터 파이프라인을 넘어서, MLops까지 범주를 확장하여 All-in-one 데이터 리터러시 플랫폼이 되고자 합니다. 프로젝트에 도움을 주신 분들께 감사드리며, 긴 글 읽어주셔서 감사합니다.FAST: 데이터 파이프라인 이제는 웹에서 was originally published in NAVER Pay Dev Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.
안녕하세요. LINE VOOM의 추천 시스템을 개발하는 ML 엔지니어 이창현, 미디어 플랫폼 서버 개발자 조희성입니다. 저희는 지난 9월 2일부터 6일까지 개최된 사내 행사인 Te...

하이퍼커넥트는 오랜 기간 제품에 기여하는 AI 기술을 연구해 왔습니다. AI를 통해 제품에 기여한다고 하면 성과지표(KPI)를 설정하고 적당한 모델을 찾은 뒤 가능한 한 빨리 시장에 제품을 출시하는 것으로 여겨지기 쉽습니다. 반대로 연구라고 하면 논문 작성과 동일시되는 경향이 있고요. 하지만 하이퍼커넥트의 AI 조직이 일하는 방식은 이러한 일반적인 인...