마켓컬리
주소정제 서비스 내재화 - 1화 ( 줄줄 새는 돈 )
Else
문제인식과 컬리에서의 주소 정제의 목적
2025-01-20
국내 IT 기업들의 기술 블로그 글을 한 곳에서 모아보세요

문제인식과 컬리에서의 주소 정제의 목적
![[고객사례] 거성디지털(멜킨스포츠), "네이버웍스를 통해 잔무를 줄이고 업무를 효율화하여 홈트레이닝 분야 1등을 유지하고 있습니다."](https://blogthumb.pstatic.net/MjAyNTAxMTZfMjU3/MDAxNzM2OTkzMzYwMzE5.JdWhbVhPQbP_ezX5EzFs1Pch9NacV04OcHJx6ilV9oog.0N92iUHiMhhYsLYn4RTOVsS32NkJdP1uVzD5s2AzIGcg.PNG/네이버클라우드_블로그_썸네일2.001.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com 입니다. 이번 포스팅에서는 네이버웍스를 통해 업무를 효율화하고 홈트레이닝 분야 1등을 유지하고 있는 '거성디지털(멜킨스포츠)'을 소개해 드리려고 해요! 거성디지털(멜킨스포츠)은 실내 자전거, 러닝머신, 요가 매트 등 약 120개의 다양한 홈트레이닝 운동기구를 개발하고 판매하는...

“저에 대한 기댓값이 달라지는 게 느껴질 때 내가 성장했다고 생각하게 되는 것 같아요.”
![[상품 소개] 데이터 시각화의 모든 것, NIMORO](https://blogthumb.pstatic.net/MjAyNTAxMDhfMTIx/MDAxNzM2MzEyNjA0Mzc4.kN3G0y0KL3-D18Kifkfz1Ge10G-QwgurQ9qkVWwPAvUg.sptzAO84AoHKnNXd6bKAOFonh1wez80S_bnXxfYWHkgg.PNG/241129_NIMORO_썸네일.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com 입니다. 기업에게 필수적인 요소, 데이터 데이터는 비즈니스 인사이트 도출 및 효과적인 마케팅 전략을 제시하는 데에 주요한 역할을 하고 있습니다. 하지만 많은 양의 데이터를 분석하는 것에는 한계가 있어 데이터 시각화에 대한 수요는 계속해서 증가하고 있는 추세입니다. 분석된 데이...
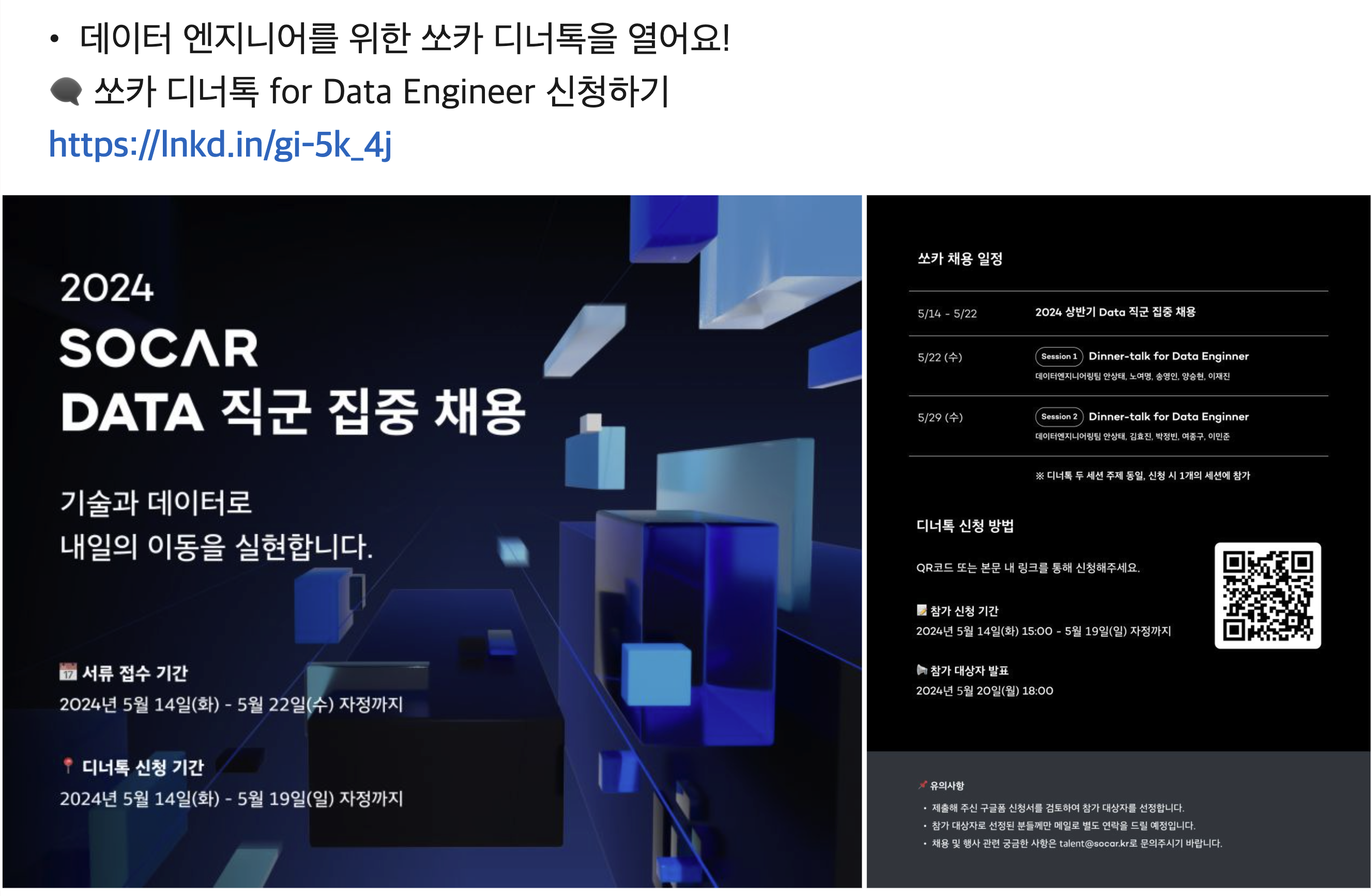
안녕하세요! 24년 9월에 쏘카 데이터엔지니어링팀에 입사한 베넷입니다. 이번 글에서는 제가 쏘카 데이터 엔지니어링팀에 합류하게 된 계기부터, 입사 후 적응 과정, 그리고 프로젝트를 통해 느낀 점들을 공유하려고 합니다. 제가 몸담은 팀의 매력과 기술적 강점을 소개해 드리겠습니다. 다음과 같은 내용에 관심이 있으신 분들이라면 이 글이 유용한 참고가 되기를...
![[2025 연말정산 총정리] 달라진 세법 개정 사항부터 절차까지, 쉽게 알려드립니다!](https://blogthumb.pstatic.net/MjAyNTAxMTVfMjIw/MDAxNzM2OTEzNzE3MTA4.yI8CqqAIMOLOAOmUuCaP8HyKWyoLZM7n2V4GGoodxNUg.nXHMo-AEEgwwizziiYfO6Qq8ycckr0cYOq9UxKNckcEg.JPEG/웍스_썸네일.jpg?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com입니다. 새롭게 맞이한 2025년, 13월의 월급을 받을 수 있는 연말정산 시즌이 돌아왔습니다! 매년 이맘때가 되면 근로자 및 업무 담당자 모두 연말정산 관련 업무로 인해 바빠지기 마련인데요. 이번 연말정산 역시 개정된 사항들이 있어 꼼꼼히 살펴보아야 합니다. 체크해야 할 부분...

안녕하세요! 29CM 에서 일관된 UI/UX 제공을 위해 디자인 시스템을 개발 및 유지보수하고 있는 프론트엔드 플랫폼 팀의 신다혜입니다.저는 현재 기존에 운영되던 Ruler 디자인 시스템을 인수인계받아 관리하고 있어요. 본래 진행하던 업무가 있었기 때문에 디자인 시스템은 0.5인의 리소스로 운영해야 했습니다.이러한 제한된 리소스 안에서 어떻게 디자인 ...
![[DAN 24] DEVIEW 세션 영상이 공개되었습니다.](https://d2.naver.com/content/images/2025/01/-----------2025-01-14------1-40-17-2.png)
기술 공유를 넘어 네이버의 미래 비즈니스와 서비스 변화 방향을 제시한 'DAN 24'가 많은 분들의 관심과 참여로 성황리에 종료되었습니다. 개발자뿐만 아니라 다양한 직군의 참가자분이 함께 기술과 서비스와 관련된 이야기를 나누다 보니 열기가 가득했는데요. 함께해 주신 여러분들께 다시 한번 감사드립니다. 모든 발표영상이 DAN 24 홈페이지와 PLAY NAVER 네이버 TV 채널에 공개 되었습니다. DAN 24 오프라인 현장에서 가장 참여율이 높았던 기술 세션들도 정리했으니 많은 관심 부탁드립니다. 1. 여러분의 웹서비스에는 꼭 필요한 것만 있나요? 번들사이즈 최소화를 통한 웹 성능 개선 - NAVER FINANCIAL 김용찬 님 수년간 운영된 서비스의 번들 사이즈를 최적화하여 성능을 크게 개선한 경험을 공유하고, 매일 여러 개의 PR이 생성되고 병합되는 저장소에서 꼭 필요한 코드만 최소한으로 포함시켜 사용자에게 효율적으로 서비스를 제공하는 방법을 소개합니다. 2. 네이버페이 결제 시스템의 성장과 변화 - NAVER FINANCIAL 김진한 님 손쉬운 확장을 위한 분산 DB와 EDA 적용, 무중단 결제를 위한 다양한 시도들과 함께 결제 서비스에 특화된 모니터링 및 SRE 활동들까지 네이버페이 성장을 견인하기 위한 기술의 변화와 경험을 공유합니다. 3. 사용자 경험을 극대화하는 AI 기반 장소 추천 시스템: LLM과 유저 데이터의 융합 - NAVER 김창회/이준걸 님 AI 기반의 장소 추천 시스템을 주제로 LLM을 추천 모델에 적용하는 과정에서 있었던 고민들과 실제 서비스 적용까지의 기술 노하우를 공유하고, 기존의 추천 모델/데이터와 어떻게 시너지를 내고 서비스 경험을 극대화할 수 있었는지를 소개합니다. 1. 사람을 대신해야 진짜 AI지?: LLM 기반 임베딩부터 검색 품질 자동 평가 모델까지 - NAVER 권오준님 Human 수준의 모델링을 위한 데이터 구축 방법론, 여러 모델의 아키텍처 및 장/단점, 학습 과정에서 발견한 노하우 등을 공유하고, 네이버에서 사용자의 검색 경험 향상을 위해 AI를 어떤 식으로 활용하고 있는지를 공유합니다. 2. 벡터 검색의 정점에 오르다: 최적의 뉴럴 검색 엔진으로 업그레이드 하기 - NAVER 현화림/김인근 님 ColBERT 및 후속 뉴럴 검색 모델들을 소개하고 각 모델을 자세히 들여다봅니다. 웹 검색에 대한 인하우스 검색 엔진 솔루션(NPP)의 부하 특성을 공유하며, 엔지니어링이 솔루션 성능에 어떤 영향을 미치는지 공유합니다. 3. 당신의 PYTHON 모델이 이븐하게 추론하지 못하는 이유 [CPU 추론/모델서빙 PYTHON 딥다이브] - NAVER 김성렬 님 Jupyter Notebook 위에서 추론하는 모델이 실 서버 환경에서 1초에 100,000번의 추론을 수행하기 위해 Python, ML Framework, Model Server 관련 어떤 지식이 필요한지를 공유합니다. [DAN 24] DEVIEW 세션 영상 더 보기 >>

"이 방향이 맞을까?" 연말, 연초가 되면 많은 PM과 리더들은 내년도 로드맵과 서비스 방향성을 고민하며 이 질문을 스스로에게 던집니다. 무엇을 우선순위에 두어야 할지, 어떤 문제를 해결해야 할지, 그리고 그 문제를 어떻게 풀어나가야 할지에 대한 답을 찾는 과정은 설레면서도 막막함을 동반하죠. 규모가 크고 복잡한 제품을 관리할수록 이러한 고민은 더 깊어질 수밖에 없습니다. 조직을 같은 방향으로 이끄는 전략이 […] The post 프로덕트 전략, 어떻게 시작해야 할까? first appeared on 우아한형제들 기술블로그.

안녕하세요? PSE(Platform Server Engineering) 파트 DevOps 이정민, 빅데이터센터 AI Lab ML engineer 박민규입니다. 이렇게 2명은 2023 AWS re:Invent를 다녀왔는데요, event 참관기를 들려 드리려 합니다!목차는 다음과 같습니다.1. AWS re:Invent 소개2. AWS re:Invent를 ...

안녕하세요 빅데이터 센터 AI Lab 황호현 입니다.저희 AI Lab에서는 리멤버 유저들에게 인공지능을 통해서 WoW한 경험을 주기 위해 Recommendation System, Ranking Model, Document Understanding, NLP등 다양한 연구를 진행하고 있습니다.이번 포스트는 입사 후 맡은 첫 번째 프로젝트인 “리멤버 커뮤니...

오늘은 UX Engineering Team Leader 조유성님의 이야기를 들어봤어요. 문과생에서 Full Stack Engineer, Frontend Engineer, UX Engineer에서 팀 리더까지 맡으신 유성님의 이야기 오늘 들려드릴게요.
안녕하세요. 커뮤니케이션 앱 LINE의 모바일 클라이언트를 개발하고 있는 Ishikawa입니다. 저희 회사는 높은 개발 생산성을 유지하기 위해 코드 품질 및 개발 문화 개선에 힘쓰...

안녕하세요! 당근 알림 경험팀에서 백엔드 엔지니어로 일하고 있는 데이(Daey)라고 해요. 알림 경험팀은 일반적인 플랫폼 조직이 아닌, 모든 유저의 알림 경험을 고민하는 서비스 조직이기도 해요. 알림 기능을 개발하다 보면 아래와 같은 말을 자주 듣곤 하는데요.“알림은 그냥 보내달라는 대로 보내면 되는 거 아닌가요?”네, 그냥 보내달라는 대로 보내면 되는 게 아니에요. 알림은 먼저 사용자에게 접근할 수 있는 강력한 수단이지만, 사용하기에 따라 긍정적 경험뿐만 아니라 부정적 경험도 줄 수 있는 양날의 검이에요. 따라서 알림 경험팀은 단순히 알림을 잘 보내기 위한 플랫폼만 만드는 게 아니라, 유저가 알림을 통해 어떤 경험을 얻어갈지도 치밀하게 고민하고 있어요.그런데 알림 경험팀에서 생각하는 모든 유저에는 단순히 당근 앱 사용자만 포함되지 않아요. 알림을 발송하는 당근의 구성원들까지도 포함하죠. 이는 알림을 발송하는 당근 구성원들의 긍정적 알림 경험이 장기적으로 당근 앱 사용자들의 긍정적 알림 경험에 기여한다고 믿기 때문이에요.이번 글에서는 알림을 받는 사용자뿐만 아니라 알림을 발송하는 당근 구성원들의 경험도 효과적으로 개선한 ‘알림 신호등 프로젝트’를 소개하려 해요. 사용자의 알림 경험을 개선하기 위한 모니터링 기준을 마련하고, 챙겨야 하는 알림들이 모니터링 결과와 함께 담당자를 직접 찾아가는 시스템을 개발한 프로젝트죠. 사용자의 경험을 개선하기 위한 알림 경험팀의 치열한 고민과 해결 방법을 공유해 드릴게요.알림 경험팀이 발견한 문제 상황저희 팀에서는 먼저 당근 앱 사용자들과 당근 구성원들의 알림 경험에 부정적인 영향을 주는 요소들을 면밀히 파악했어요. 크게 세 가지 문제점을 도출했는데요. 각 문제점이 당근 앱 사용자와 당근 구성원 각자에게 어떤 영향을 미치는지 구체적으로 설명해 드릴게요.1. 방치된 알림더 이상 발송하지 않는 알림이 발송 가능한 상태로 남아있는 경우를 생각해 보세요. 이렇게 방치된 알림들은 당근 사용자들의 알림 경험에 어떤 영향을 미칠까요? 예를 들어 22대 국회의원 선거 알림이 지금 발송된다면 어떨까요? 왜 이 알림이 지금 발송됐는지 의아해하며 부정적인 알림 경험이 쌓일 거예요.이런 경우도 한번 생각해 봅시다. 최근 당근 알림함은 스레드 알림 형태로 변경되었는데요.예 - 스레드 알림함스레드 알림에는 알림들을 스레드의 형태로 묶어줄 스레드 제목이 필요해요. 예를 들어 사진 속 알림의 스레드 제목은 ‘동네생활’이고, 알림 내용은 ‘구미동 인기글 확인하실 daeung님 구해요’인 것처럼 말이에요. 그런데 만약 스레드 설정이 되어 있지 않은 알림이 스레드 알림함에 노출된다면 어떨까요? 일반 알림에는 이런 정보들이 입력되어 있지 않기 때문에, 이런 알림이 스레드 알림함에 노출된다면 알림 내용이나 제목이 누락될 수 있어요.이런 상황을 방지하기 위해서는 당근 구성원들이 기존에 설정해 둔 알림들을 주기적으로 살펴봐야 해요. 불필요해진 알림을 제거하거나 내용 업데이트가 필요한 알림들을 수정해야 하죠. 그런데 현실적으로 다른 업무들을 살피다 보면 알림을 일일이 확인하는 작업을 놓치게 되어, 위에서 살펴본 상황들이 종종 발생하곤 해요.2. 알림 오픈율 분석오픈율은 매우 중요한 지표예요. 사용자들에게 해당 알림이 필요했는지 가장 명확하게 보여주기 때문이죠. 만약 사용자에게 필요한 알림이었다면 사용자들은 알림을 오픈해 내용을 확인했을 거예요. 반대로 필요하지 않았다면 굳이 알림을 오픈하지 않겠죠. 따라서 사용자의 알림 경험 향상을 위해선 오픈율이 낮은 알림의 원인을 파악하고 개선하는 작업이 매우 중요해요.하지만 단일 알림의 오픈율만으로는 그 수치가 높은지 낮은지 판단하기가 어려워요. 예를 들어 한 사용자가 인테리어 업체에 댓글로 문의 사항을 남겼다고 가정해 볼까요? 거기에 답글이 달렸다는 알림이 뜬다면, 대부분의 사용자는 확인하는 즉시 곧바로 열어볼 거예요. 사용자가 궁금해하는 중요한 정보가 담겨 있으니까요. 본인 댓글에 대한 답글 알림은 상대적으로 오픈율이 높을 수밖에 없죠. 반면 할인 쿠폰을 사용해 보라는 등의 광고성 알림은 대체로 오픈율이 낮을 거예요.예 - 정보성 알림예 - 광고성 알림알림 경험팀에서는 비슷한 발송 맥락을 가진 알림들을 묶어 알림 카테고리라는 정보를 제공하고 있어요. 카테고리가 동일한 알림들의 오픈율을 분석하면, 관리하고 있는 개별 알림의 오픈율이 높은지 낮은지를 알 수 있을 거예요. 하지만 여기에도 한계는 있어요. 당근의 개별 구성원들은 어떠한 방식으로 알림 카테고리가 구성되는지 그 맥락을 모두 알기 힘들기 때문이에요. 만약 알고 있다 하더라도 개별 구성원들이 각자 자신이 관리하는 오픈율을 분석하기 위해 다른 카테고리의 알림들까지도 확인하는 것은 매우 비효율적이죠.3. 알림 피로도 관리Facebook의 연구 결과에 따르면 알림 발송량을 줄이면 단기적으로는 관련 지표가 악화되지만, 장기적으로는 오히려 지표가 향상된다고 해요. 이는 사용자들의 알림 피로도 관리가 매우 중요하다는 것을 시사해요. 너무 많은 알림을 받게 되면 사용자들은 알림 자체에 피로감을 느끼게 될 거예요. 그렇게 되면 중요한 알림마저도 사용자에게 제대로 전달되지 않을 수 있어요.따라서 알림 피로도를 파악하는 것이 중요해요. 알림 발송량과 알림 수신 거부량을 분석하면 사용자들의 알림 피로도를 가늠할 수 있어요. 알림 발송량이 지나치게 늘어나면 일반적으로 사용자들은 알림에 대한 거부감을 느끼게 되고, 그에 따라 수신 거부 처리가 증가할 것이기 때문이죠.하지만 알림 발송량의 총량을 줄이는 것은 매우 어려운 일이에요. 자신이 발송하는 알림이 굳이 보낼 필요가 없다고 생각하는 당근 구성원이 몇 명이나 있을까요? 또한 알림의 발송량은 서비스의 성장에 의해 자연스럽게 증가할 수도 있는데, 기계적으로 발송량을 제한해서 서비스 성장을 방해할 수도 없는 노릇이고요.알림 경험팀의 해결책1. 모니터링 기준 마련알림 경험팀에서는 각 문제에 대해 가장 먼저 다음과 같은 모니터링 기준을 마련했어요.방치된 알림아래와 같은 기준을 가지고 방치된 알림 모니터링을 수행하기로 결정했어요.30일간 알림 발송이 없는 경우 → 방치된 알림으로 간주30일 이상의 주기를 가지고 알림이 발송되는 경우 → 방치된 알림에서 제외미래에 발송이 예약되어 있는 경우 → 방치된 알림에서 제외기본적으로 30일간 알림 발송이 없는 경우를 방치된 알림으로 간주해요. 하지만 가계부 알림과 같이 꾸준히 사용하는 알림이지만, 발송 주기가 한 달을 넘는 경우가 있어요. 따라서 주기 발송이 설정되어 있거나 미래에 예약 발송이 설정되어 있는 경우는 방치된 알림에서 제외했어요.알림 오픈율 분석오픈율 모니터링의 경우 알림 카테고리별 권장 오픈율을 계산하여, 권장 오픈율보다 높은지 낮은지를 확인했어요. 이때 권장 오픈율은 해당 알림 카테고리에서 극단값을 제거하고 중간값을 선택했죠. 극단값을 제거한 이유는 때때로 테스트 발송이나 특수한 상황으로 인해 오픈율이 100% 또는 0%가 되는 경우가 있기 때문이에요. 이러한 극단값을 그대로 반영하면 실제 오픈율을 왜곡할 수 있어요. 또한 알림 오픈율의 분포가 정규분포를 따르지 않는 경우가 많은데요. 이 경우 평균값은 대표성이 떨어질 수 있기 때문에 중간값을 기준으로 삼았어요.알림 피로도 관리알림 피로도 관리를 위해 알림 발송량과 수신 거부량을 모니터링했어요. 단순히 알림 발송량을 기계적으로 줄이는 것은 상황에 따라 부작용을 일으킬 수 있어요. 따라서 이상치 탐지 기법을 우선적으로 도입하기로 했어요. 알림 발송량 추이나 수신 거부량 추이를 급격하게 벗어나는 경우를 모니터링하기로 한 거예요.이상치 탐지에는 사분위 수 기반 기법을 적용했어요. 이는 권장 오픈율 분석과 마찬가지로, 극단값이 존재하고 정규분포를 따르지 않는 경우가 많기 때문이에요. 평균 및 표준편차 기반의 방식보다는 사분위 수 기반 방식이 더 적절할 것으로 판단했어요.(통계적으로 이상치를 탐지하는 방법을 더 구체적으로 알고 싶은 분은 이 글을 참고하면 도움이 될 거예요.)2. 당근 구성원을 찾아가는 모니터링하지만 알림 경험을 효과적으로 개선하려면 모니터링 기준을 세우는 것만으로는 부족해요. 사용자의 긍정적인 알림 경험을 위해서는 당근 구성원의 관심과 노력 또한 필수적이에요. 예를 들어 30일간 알림 발송이 없어서 방치된 알림으로 간주하는 경우, 담당자가 해당 알림들을 확인하고 발송 불가능한 상태로 처리해야 해요. 또한 권장 오픈율보다 낮거나 알림 발송량 및 수신 거부량에 급격한 증가가 생기는 경우, 그 이유를 면밀히 분석하여 개선해 나가는 작업이 필요해요.다시 말해 당근 구성원들은 알림 센터*의 기능과 관련된 여러 일들을 직접 일일이 챙겨야 하는 상황이었어요. 그런데 만약 스스로 챙기지 않아도, 해야 할 일들이 당근 구성원들을 찾아오게 만들 수 있다면 어떨까요? 모니터링 기준을 충족하지 못하는 알림들을 슬랙이나 알림 센터를 통해 알려준다거나 하면 말이에요. 위와 같은 문제 상황을 방지하면서, 당근 구성원들의 알림 경험 또한 개선할 수 있을 거예요. 그래서 저희 팀에서는 모니터링 결과를 당근 구성원들에게 자동으로 전달하는 모니터링 시스템인 ‘알림 신호등’을 개발하기 시작했어요.알림 센터: 당근 구성원들이 알림 발송을 위해 사용하는 백오피스를 의미해요.예 - 슬랙 알림을 통한 모니터링 결과 확인예 - 알림 센터를 통한 모니터링 결과 확인알림 신호등의 구조알림 신호등의 구조는 다음과 같아요.다양한 알림 관련 데이터를 이용해 모니터링을 수행해요.모니터링 기준을 충족하지 못하는 경우 모니터링 결과를 저장하고 슬랙 알림을 발송해요.알림 센터에서 모니터링 결과 조회 기능을 제공해요.모니터링 기준을 손쉽게 확장할 수 있는 구조좋은 알림 경험을 제공하기 위해서는 다양한 측면에서의 모니터링이 필요해요. 지금은 일정 기간 동안 알림이 발송되지 않는 경우, 알림 실험이 장기화되고 있는 경우, 알림 발송량이나 알림 수신 거부 추이에 변동이 생기는 경우에 대해서만 모니터링을 수행하고 있지만, 추후 새로운 기능이 추가되면 해당 기능에 대한 모니터링이 필요해질 수도 있죠.따라서 이러한 요구사항을 충족시킬 수 있도록 확장성 있는 구조가 필요했어요. 이를 위해 모니터링 기준을 추상화된 인터페이스로 정의하고, 각 기준별 Checker를 구현하는 방식으로 설계했어요. 이를 통해 새로운 모니터링 기준이 추가되더라도 해당 Checker만 구현하면 되는 유연한 구조를 갖출 수 있었어요.모니터링 기준을 정의할 때, 각 기준별로 충족 여부를 확인하는 로직을 추상화된 MonitoringChecker 인터페이스로 정의했어요.type MonitoringChecker interface { Check(<모니터링 대상 알림>) (bool, error)}Check 메서드를 이용해 주어진 알림 시나리오가 해당 모니터링 기준을 충족하는지 여부를 판단하고, 그 결과를 boolean 값으로 반환해요.이를 통해 정의한 모니터링 기준들에 대해 각각의 Checker 를 구현했어요. 예를 들어 “30일 동안 알림 발송이 없다”는 기준에 대한 Checker는 다음과 같아요.type NoNotificationsIn30DaysChecker struct { // 필요한 의존성 주입}func (c *NoNotificationsIn30DaysChecker) Check(<모니터링 대상 알림>) (bool, error) { // 30일 간 알림 발송 내역 조회 // 발송 내역이 없는 경우 true 반환}결과그 결과, 이전 대비 발송 불가 처리된 알림의 비율이 약 130% 증가했어요. 불필요한 알림을 제외하고 사용자에게 보다 정돈된 알림 경험을 제공하게 된 거예요. 더 이상 발송돼서는 안 되는 알림들 때문에 사용자가 혼란을 겪는 일이 줄어들었어요.앞으로의 과제권장 오픈율과 알림 발송량, 수신 거부량 이상치 탐지의 경우 아직 기능을 활발히 테스트 중이에요. 어느 정도의 오픈율, 알림 발송량, 수신 거부량이 적절한 수준인지 논의를 마친 상태는 아니에요. 하지만 실험 결과를 꾸준히 확인하면서 선제적으로 기준치를 당근 구성원들에게 제시하고 있어요. 실험이 마무리되면 다시 한번 논의를 통해 건강한 알림 경험을 더 명확히 정의하고자 해요.또한 알림 신호등을 도입한 게 처음이기 때문에 아직 구체적으로 개선할 부분들이 많은데요. 예를 들어 알림 발송량 이상치 탐지 방식에는 한계가 존재해요. 단순한 통계 기반 방식으로는 알림 발송량이 0으로 떨어지는 경우를 효과적으로 탐지하기가 어렵죠. 필요한 알림들이 발송되지 않는다는 측면에서는 중요한 지표일 수도 있지만, 알림 피로도에는 영향을 미치지 않기 때문이에요. 따라서 이러한 한계를 극복하기 위해 좀 더 고도화된 기법을 고민 중이에요. 시계열 분석 알고리즘이나 머신러닝 기법 등을 활용해 알림 모니터링의 정확성과 민감성을 높여보려고 해요.당근 구성원들에게 슬랙 메시지나 알림 센터를 통해 모니터링 결과를 제공하는 방식에도 한계가 있어요. 대부분의 당근 구성원들은 여러 개의 알림을 동시에 관리하는데, 슬랙 알림이나 알림 센터에서는 개별 알림 단위로 결과를 제공하기 때문이에요. 구성원들은 여전히 자신이 관리하는 여러 개의 알림들을 하나하나 확인해야 하죠. 번거로움이 완전히 해소되지는 않은 거예요. 따라서 개선이 필요한 알림들을 한눈에 확인할 수 있는 대시보드를 만들고 있어요. 대시보드가 제공되면 구성원들은 알림 센터에 접속 후 어떤 알림에 대해 무엇을 해야 하는지 직관적으로 파악하게 될 거예요.마치며지금까지 살펴본 ‘알림 신호등 프로젝트’를 통해 알림 경험팀은 앞으로 어떤 방향으로 나아가야 할지 확신할 수 있었어요. 저도 개인적으로 문제정의부터 해결책을 도출하고 팀원들을 설득하는 것까지, 여러 과정을 거치며 팀의 일원으로서 큰 성장을 이뤄낼 수도 있었고요.알림 경험팀은 앞으로 단순한 플랫폼 조직이 아니라 서비스 조직으로서 당근 앱 사용자와 당근 구성원들의 알림 경험을 개선해 나갈 예정이에요. 부정적 알림 경험을 방지하는 것뿐만 아니라, 사용자에게 긍정적 알림 경험을 적극적으로 제공하기 위해 노력하려고 해요. 예를 들어 사용자에게 꼭 필요한 알림을 발굴하는 기능처럼 사용자가 실질적인 도움을 받을 수 있는 유의미한 알림을 제공하고자 해요.당근 앱 사용자와 당근 구성원들의 알림 경험을 위해 치열하게 고민하는 저희 팀에 흥미가 생기셨다면, 알림 경험팀의 문은 항상 열려있어요!아래 채용 공고를 통해 저희 팀에 합류할 수 있으니 많은 관심 부탁드려요! :)Software Engineer, Backend — Notifications Experience모두를 위한 알림 경험 만들기 was originally published in 당근 테크 블로그 on Medium, where people are continuing the conversation by highlighting and responding to this story.
이 글은 카프카(Kafka)를 사용하는 스프링 환경에서 메시지 처리 속도를 동적으로 조절해야하는 상황과 여러 쓰로틀링 기법들을 소개합니다. 카프카를 사용하는 스프링 프레임워크 환경에 익숙하고, 카프카의 기본 개념 및 컨슈머와 컨슈머 그룹, 파티션 구조를 이해하는 독자를 대상으로 작성되었습니다. 모든 예제의 전체 소스코드는 GitHub 저장소에서 확인하실 수 있습니다. 분산 서버에서 대규모의 요청이 발생할 때 수평 확장을 통해 처리량을 늘릴 […] The post 카프카 컨슈머에 동적 쓰로틀링 적용하기 first appeared on 우아한형제들 기술블로그.
안녕하세요. 커뮤니케이션 앱 LINE의 모바일 클라이언트를 개발하고 있는 Ishikawa입니다. 저희 회사는 높은 개발 생산성을 유지하기 위해 코드 품질 및 개발 문화 개선에 힘쓰...
![[네이버클라우드캠프] 2024 특별 커리어 성장 세미나 <커리어, 함께 Carry On> 현장 스케치](https://blogthumb.pstatic.net/MjAyNTAxMDdfMTQ5/MDAxNzM2MjE0OTMyODI5.dD_3udVcPDYsxNfXDEUsLEzjnmDBkLzaTzStrMacPZAg.t0g1ujWyunA3uDNeUAqaZCAPLDGUMaWolLhz3uoC1zog.PNG/thumb.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com입니다. #네이버클라우드 #네이버클라우드캠프#네클캠 #K-Digital Training #KDT #Together We Rise #성장 세미나 #성장세미나 지난 12월 11일 수요일, 네이버클라우드캠프 2024 특별 커리어 성장세미나 K-Digital Training 과정 설명...

stockcake.com안녕하세요. 29CM 모바일팀 iOS 개발자 김중원입니다. 이번 글에서는 앱 시작 시간을 개선하기 위해 새 기술을 도입하고 이를 정량적으로 평가하기 위한 인프라를 구축하여 명확한 성과를 확인한 내용을 공유드립니다.29CM 모바일 앱은 높은 수준의 성능 유지를 목표로 성능 지표 설정과 정량적 측정을 위해 2분기 과제로 앱 성능 측...

This article is the last in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Need ...
![[프로그램] CSAP 인증 기업 이용 1위! 네이버클라우드가 준비한 공공 SaaS 지원 프로그램](https://blogthumb.pstatic.net/MjAyNDEyMTdfMTg3/MDAxNzM0NDIxMDc5MDU3.Vq057BNFtwOUIrTuQeqzJFAgLYM1XjfGaIL3kwFGhPEg.aHp_oPxeC2oMxNuiX7VEt16BhM4y3aXeduDQlCUA89Qg.PNG/241217_공공saas썸네일.png?type=s3)
공공 SaaS 시장 진출이 목표지만 CSAP 인증 평가가 고민인 기업들 주목! 공공 SaaS 비즈니스에 필수인, CSAP 획득 심사. 어디서부터 시작해야 할지, 막막하셨나요? *CSAP (클라우드 서비스 보안인증) 한국인터넷진흥원 (KISA)에서 지원하는 클라우드 서비스 보안 관련 인증 제도로 공급자가 제공하는 서비스의 정보보호 기준 준수 여부 평가 ...
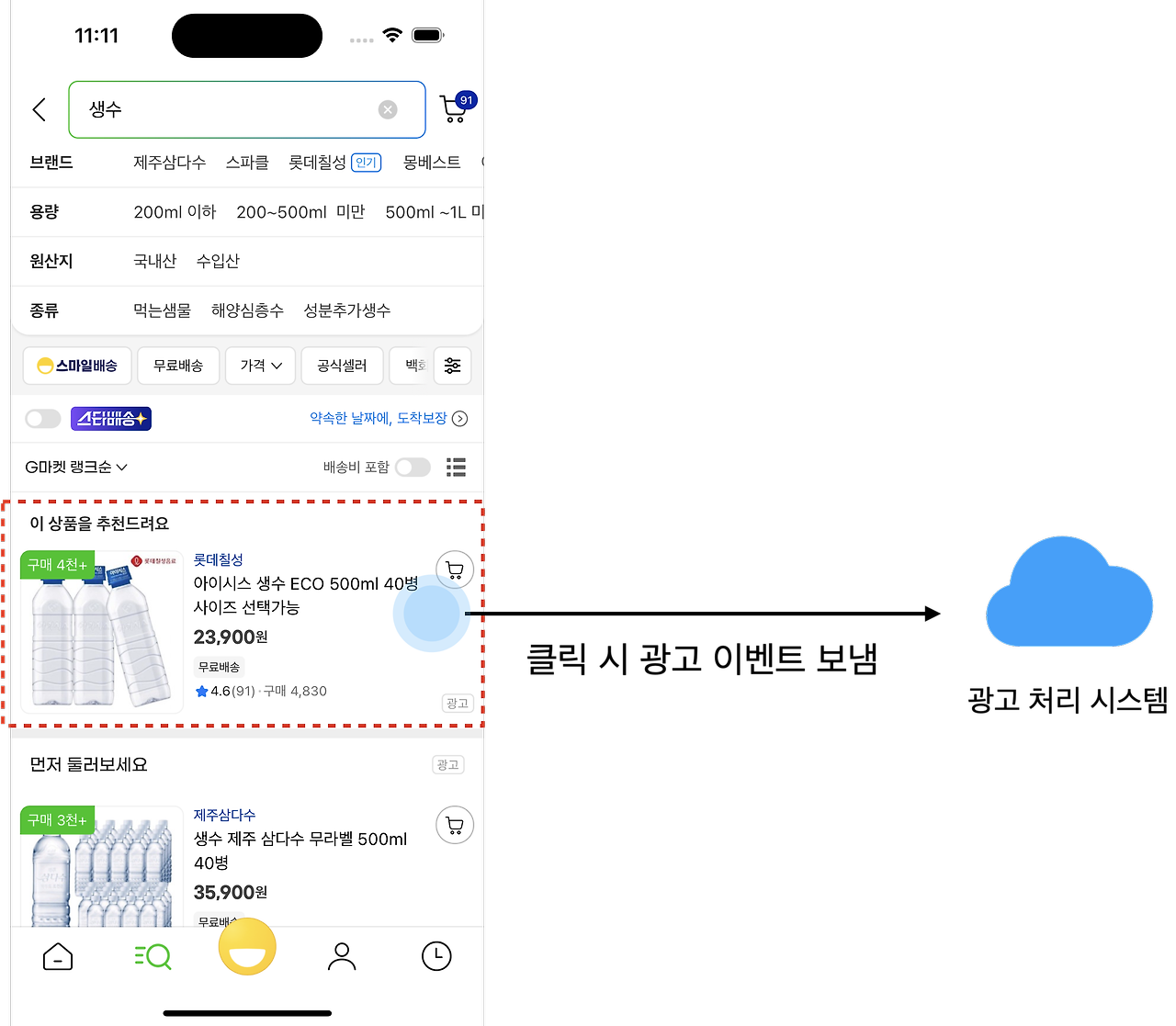
안녕하세요 지마켓 Mobile Application Team 강수진입니다. 오늘은 iOS에서 특정 이벤트에 대한 URL 요청이 정상적으로 이루어졌는지 확인하는 방법에 대해 알아보겠습니다. 들어가기 전에 모든 서비스에서 광고는 중요합니다. 왜냐하면 수익과 직결되기 때문이죠 지마켓도 곳곳에 다양한 유형의 광고가 포함되어 있는데요! 일례로...
들어가며 LINE Plus의 MPR(Mobile Productive & Research) 팀은 LINE 클라이언트 앱의 빌드 개선과 CI 파이프라인 관리, 자동화 지원 등의 업무를...
요즘 QA…
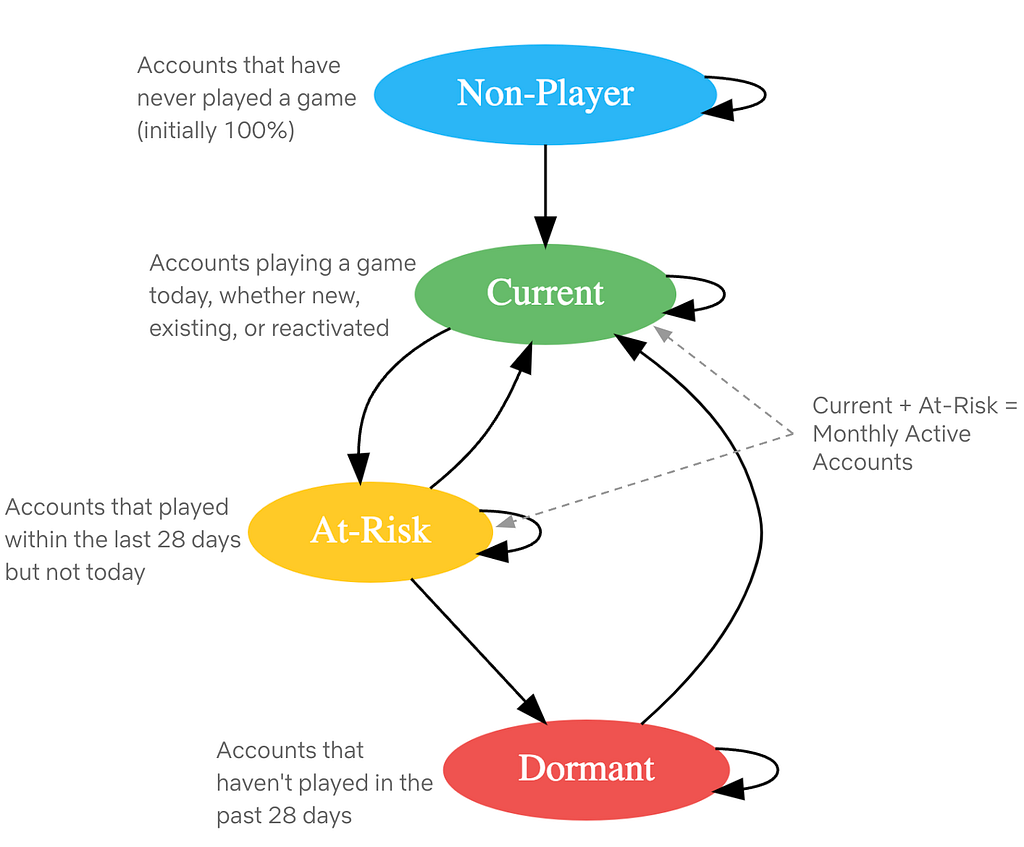
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Nee...
안녕하세요.Pricing Tech Engineering팀원이자 해당 테크블로그의 에디터장을 담당하고 있는 김민우입니다. 본격적인 글에 앞서 이번에 작업한 테크블로그 UI 변경 건을 잠깐 소개해드립니다. G마켓 테크블로그는 티스토리를 기반으로 제작되었으며, 티스토리에서 ...
![[캘린더️] 1월 무료 교육 웨비나 일정 모음](https://blogthumb.pstatic.net/MjAyNTAxMDJfMjU2/MDAxNzM1Nzg1MjMwODEz.lrRl3k0HChhr0s7dNQHY689INJu8VD8moTXF23ek_F4g.bEXTCsFkHS4kYjWjLVN_Pz86HvFv8lWv6xlwV1DPPbMg.PNG/2501_edu_thumb.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com 입니다.
![[웍스 사용 설명서] 중요한 업무 메일 놓치지 않는 법](https://blogthumb.pstatic.net/MjAyNTAxMTVfNzUg/MDAxNzM2OTExMjI5NTk5.8ljmuzBNTKv9lFHFLw6zA0ABO8XOq92ixacHFkk_5OEg.jFQf7gR_p3B8BRoQ_C6zEQ2STjExdh-TVb6Po4iANo0g.JPEG/웍사설메일.jpg?type=s3)
안녕하세요, 협업과 소통을 위한 필수 기능으로 글로벌 53만 기업의 든든한 협업툴 역할을 해온 네이버웍스(NAVER WORKS)입니다! 정신없는 업무 시간, 하루에도 수십 통씩 쏟아지는 메일들을 어떻게 관리하고 계시나요? 메일을 읽었지만 즉시 회신하기 어렵거나 메일로 요청받은 업무를 바로 처리하기 불가능한 경우, 받은 메일함에 용도/목적이 다른 메일들...
딜리버리 프로덕트 개발팀에서 안정적인 서비스 제공을 위한 고군분투기

…
지난 2편에서는 가상 스레드(virtual thread)의 컨텍스트 스위칭(context switching)이 구체적으로 어떤 과정으로 진행되는지 알아봤습니다. 마지막 3편에서는 ...