당근마켓
당근의 사용자 행동 로그 관리 플랫폼: 이벤트센터 개발기
백엔드
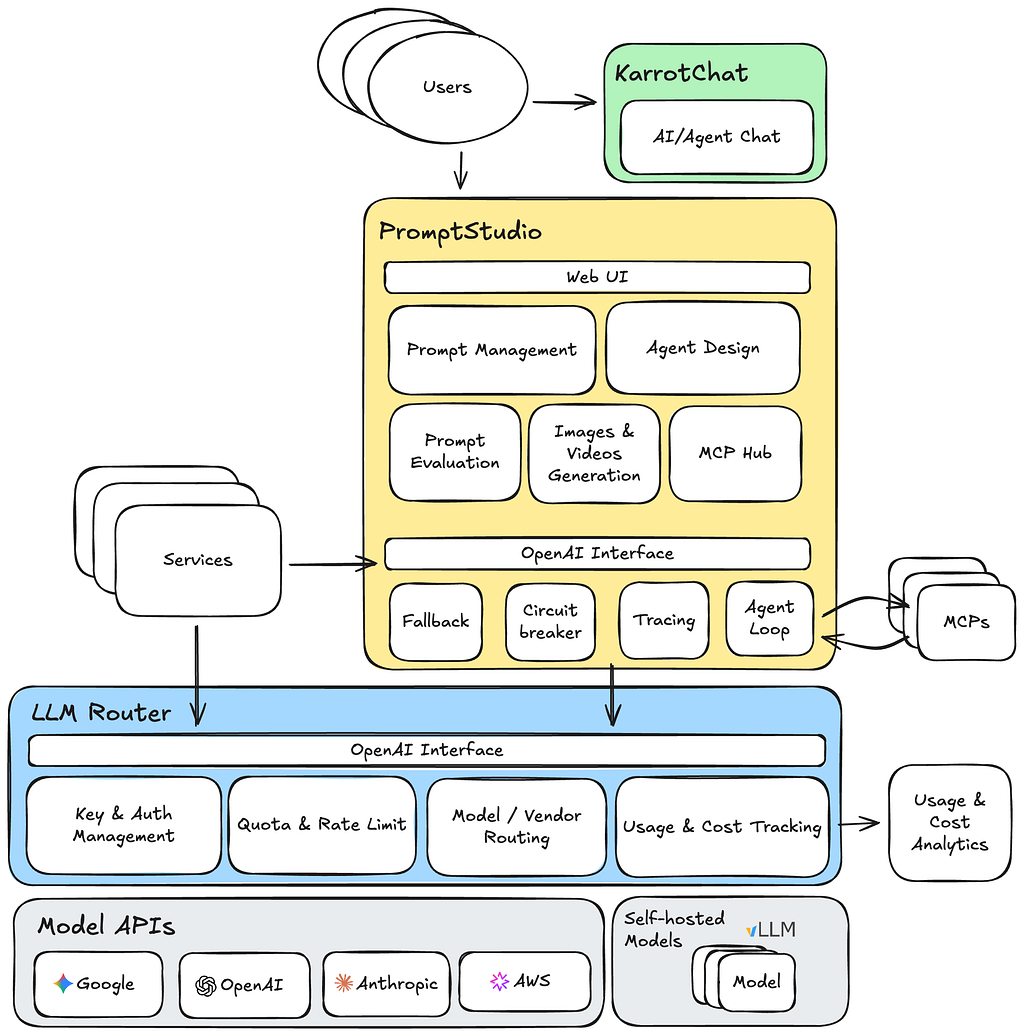
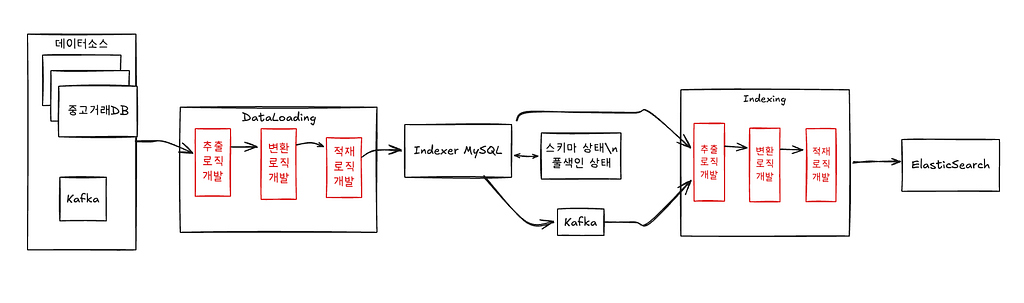
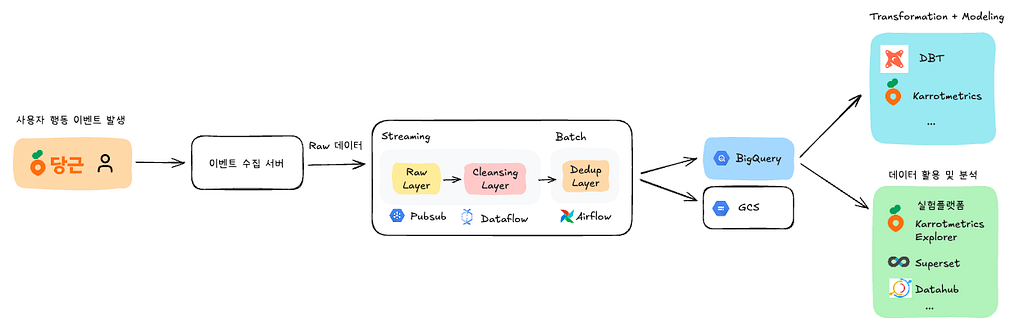
코드로 관리하던 사용자 행동 로그를 플랫폼으로 만든 이유안녕하세요. 당근 데이터가치화에서 프론트엔드 엔지니어로 일하고 있는 미카(Mika.kang)예요.당근에서는 수많은 사용자 행동 로그가 매일 쌓이고 있어요. 이 로그들은 실험을 설계하고, 제품을 개선하고, 의사결정을 내리는 데 중요한 역할을 해요. 하지만 로그가 많아질수록 관리 방식의 중요성도 함께...
2026-01-08