안녕하세요, 당근 프로덕트 디자이너 Ina입니다.당근의 웹사이트를 알고 계신가요? 당근 웹사이트에서는 당근의 다양한 서비스를 앱 설치 없이도 만나볼 수 있는데요. 사용자들에게 당근의 매력을 알리는 중요한 창구예요.당근 웹사이트: https://www.daangn.com/Karrot 글로벌 웹사이트(캐나다): https://www.karrotmarket.com/ca/Karrot 글로벌 웹사이트(일본): https://www.karrotmarket.com/jp/이번 글에서는 당근의 글로벌 서비스 Karrot의 사용자들이 웹에서도 당근을 쉽게 만날 수 있도록, 북미와 일본 지역을 대상으로 검색 엔진 최적화(SEO)를 강화하고 자연스럽게 앱 설치로 이어지는 매물 중심 탐색 경험을 개선한 웹사이트 프로젝트를 공유해보려고 해요.SEO란 무엇일까요?SEO(Search Engine Optimization)는 검색 엔진 최적화를 의미해요. 구글이나 네이버 같은 검색엔진에서 사용자가 원하는 정보를 검색했을 때, 당근의 웹사이트가 상단에 노출되도록 만드는 작업이에요.예를 들어, “중고 아이폰 15”라는 키워드를 검색했을 때 당근 웹사이트가 검색 결과 첫 페이지에 노출된다면, 더 많은 사람들이 사이트를 방문하게 될 거예요. 이는 곧 서비스 성장으로도 이어지겠죠.즉, SEO는 검색 결과에서의 노출뿐만 아니라 사용자와의 연결을 강화하는 필수 전략이라고 볼 수 있어요.SEO를 위한 유저 경험 만들기이 프로젝트의 핵심은 당근 웹사이트의 검색 랭킹을 높이기 위해, 다음 세 가지 요소를 충족시키는 것이었어요:관련성(Relevance): 사용자가 실제로 원하는 키워드와 유용한 콘텐츠 제공품질(Quality): 신뢰도를 높이는 양질의 콘텐츠 및 백링크사용성(Usability): 모바일 친화성, 페이지 속도, 보안 등 사용자 중심의 사이트 환경위와 같은 기술적인 SEO 목표를 달성하면서, 동시에 사용자 만족을 높이기 위해선 어떤 경험이 필요할까요?저는 이 문제를 해결하기 위해 당근의 디자인 원칙 세 가지와 검색 랭킹을 높이기 위한 기술적 솔루션 세 가지를 매칭해보고자 했어요.연결된 경험 — 관련성(Relevance)직관적인 경험 — 품질(Quality)사용자를 위한 개선 — 사용성(Usability)(참고) 당근의 디자인 원칙 7가지1. 연결된 경험2. 사용자를 위한 개선3. 직관적인 경험4. 하나의 화면 하나의 목표5. 단순한 시각 요소6. 적절한 피드백7. 간결한 문구1. 관련성(Relevance)을 위해 ‘연결된 경험’을 제공해요맥락에 맞는 키워드를 배치해요사용자들이 실제로 많이 검색하는 키워드를 자연스럽게 배치하고자 검색 결과 페이지에 필터를 추가했어요.필터는 탐색 편의를 높여요. 동시에 필터에 포함된 키워드가 검색 결과에도 노출되죠. 따라서 사용자 경험과 SEO 모두에 긍정적인 영향을 줘요.그 외에도 검색창 아래에 인기 키워드를 배치하는 등 키워드가 노출되는 곳을 다양하게 늘려나가고자 했어요.지역 설정 기능을 제공해요당근을 떠올리면 가장 먼저 생각나는 ‘동네’ 키워드를 웹사이트에 녹여내기 위해, 동네 설정과 검색 기능을 추가했어요.이를 통해 사용자는 동네에서 거래되는 물건을 쉽게 확인할 수 있게 되었어요. 또한 검색 엔진에서 ‘서초동’ + ‘소파’ 같은 지역 키워드를 함께 입력했을 때도 자연스럽게 당근 웹사이트를 만나볼 수 있게 되었어요.2. 품질(Quality)을 위해 ‘직관적인 경험’을 제공해요카테고리 목록을 추가해요글로벌 Karrot은 중고거래 서비스만 제공하고 있어요. 그래서 카테고리 페이지를 추가해 사용자들이 어떤 카테고리가 있는지 한눈에 파악하도록 돕고, 카테고리 자체로도 검색 결과가 보일 수 있도록 개선했어요.카테고리 자체가 검색 결과가 되도록 노출하기카테고리도 하나의 검색 결과로 만들며 검색 엔진에 노출되도록 개선했어요브레드크럼(Breadcrumb)을 추가해요“홈 > 부동산 > 매물”처럼 현재 위치와 다음 동선을 한눈에 파악할 수 있도록 내비게이션 흐름을 구성했어요.브레드크럼(Breadcrumb)은 사이트 품질을 높여요. 동시에 사용자에게 지금 어느 페이지에 있고 이전에 어떤 페이지를 거쳤는지를 명확히 알려줘, 직관적인 탐색 경험을 강화해요.3. 사용성(Usability)을 위해 사용자를 위한 개선을 만들어요반응형 디자인글로벌의 다양한 디바이스 환경을 고려해, 화면 크기에 따른 배치·컴포넌트를 6가지 브레이크포인트로 정교하게 설계했어요. 그 결과, 모바일 디바이스·태블릿·웹 등 다양한 환경에서도 웹사이트를 불편함 없이 이용할 수 있게 되어, 사용성(Usability)이 크게 향상됐어요.결과배포 한 달 이후의 결과예요🇨🇦 북미(캐나다): Impression(노출) 약 20배 성장, 클릭이 2배 성장했어요.배포 이후의 성장 그래프🇰🇷 한국 (24년 11월 초에 동일한 UX/UI로 개편) : 월 접속자 수 약 43% 상승했어요. (기존 426만 → 610만)마치며이번 프로젝트는 ‘관련성(Relevance)’, ‘품질(Quality)’, ‘사용성(Usability)’의 세 가지 핵심 요소를 사용자 중심의 디자인으로 풀어낸 SEO 전략으로, 당근의 웹사이트가 더 많은 사용자에게 노출되고 건강하게 성장할 수 있는 발판을 마련한 프로젝트라 뜻깊게 참여할 수 있었어요.이 프로젝트에 함께해 준 토니, 리바이, 리아, 헤일리, 해나, 브랜딩팀 리지, 쿄, 유니와 이어서 웹사이트를 널리 알리는데 애써주시는 SEO Growth 팀에게 응원과 감사의 마음을 전해요!건강한 SEO로 성장하는 웹사이트 만들기 was originally published in 당근 테크 블로그 on Medium, where people are continuing the conversation by highlighting and responding to this story.
기술 블로그 모음
국내 IT 기업들의 기술 블로그 글을 한 곳에서 모아보세요

이 글에서는 글로벌 컨퍼런스인 COP29, CES 2025, WEF 2025에서 강조한 ESG 관련 메시지를 통해 ESG 경영에 영향을 미칠 수 있는 주요 이슈들을 재조명하고자 합니다.
이직 / 팀 이동 후 어색한 코드를 내 코드로 녹여내기까지의 여정을 공유합니다.

 # 들어가며 안녕하세요. NHN Cloud의 클라우드AI팀 이태형입니다. 로그 데이터가...

본 글은 2024년도 12월에 올리브영 테크플랫폼센터 오거나이저에 의해 작성되었습니다. 새로운 경험의 서막: 마곡의 한 호텔 연회장에 모인 올리브영 엔지니어들 2024년 11월 1…
이 전망은 삼성SDS 마케팅팀 MI그룹에서 2024년 말에 400여 명의 국내 IT 의사결정 관계자를 대상으로 실시한 설문 결과로서, 2025년도에 직면할 국내기업의 경영 환경과 IT 투자 전망 중 서비스산업을 집중 분석하였습니다.
![[네이버클라우드캠프] 2024 네이버클라우드캠프 서포터즈 해단식 현장 스케치✨](https://blogthumb.pstatic.net/MjAyNTAyMjdfMjA0/MDAxNzQwNjM1ODEwMzQ0.wbJ621bjHLFq_xqnRs_-AYDAEP6OElrzv8kb3e7lNTwg.Poz3jcBPY8DbTJo1Pw-Oe9GCLqsD_r4Ckd9Unw0L7Pcg.PNG/thumb-4.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드(ncloud.com)입니다. #네이버클라우드 #네이버클라우드캠프 #네이버클라우드캠프서포터즈 지난 1월 17일 오후, 네이버 파트너 스퀘어 역삼에서는 '2024 네이버클라우드캠프 서포터즈 해단식'이 진행되었습니다. 서포터즈 분들은 지난 3개월간 엄청난 열정과 솜씨로 네이버클라우드캠프 소식들을 콘텐...
이 전망은 삼성SDS 마케팅팀 MI그룹에서 2024년 말에 400여 명의 국내 IT 의사결정 관계자를 대상으로 실시한 설문 결과로서, 2025년도에 직면할 국내기업의 경영 환경과 IT 투자 전망 중 유통/리테일 산업을 집중 분석하였습니다.
![[프로모션] 스마트 팩토리 솔루션사, 지금이 타이밍인 이유⏳](https://blogthumb.pstatic.net/MjAyNTAyMjZfNDgg/MDAxNzQwNTY0Mzg4NTky.mdbx1vGTaylV5f8M9A_DBe8NqYmCq0CZDth78pKX_Aog.PSg00idt19kM7G4uQavaSurNGNmFHEdejOueWy7Jtfsg.PNG/mfg_thumb.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com입니다. 오직 네이버클라우드에서만 제조 솔루션사 통합 지원 프로그램 네이버클라우드는 제조 DX에 앞장서는 제조 솔루션사가 클라우드와 AI로 급변하는 기술 트렌드 속에서 경쟁력을 갖출 수 있게 돕습니다. 지금 바로 프로그램 지원하고 클라우드 사업 구조 안착 지원, 비용 절감 + ...
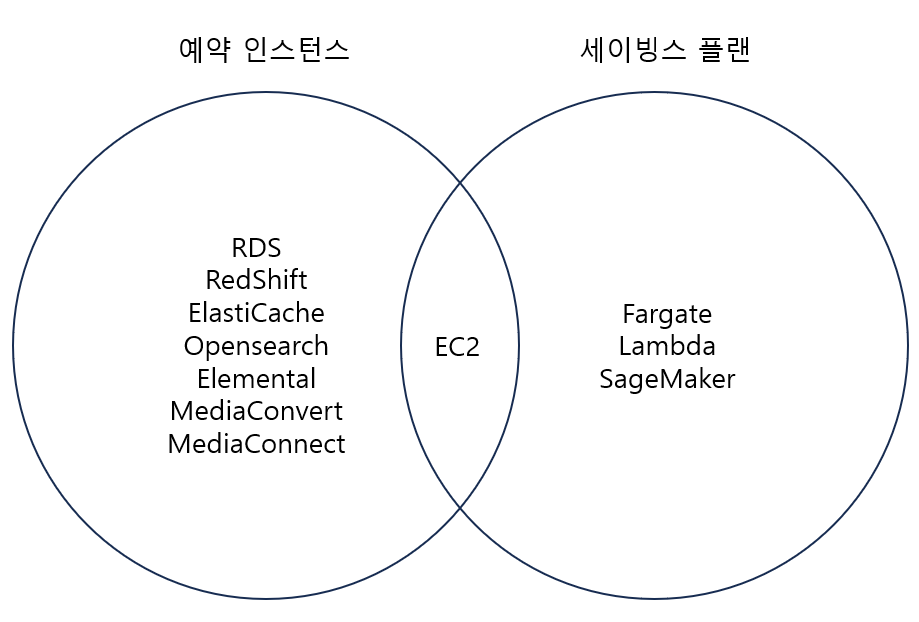
흔히 사용되는 AWS 제품 중 EC2, RDS, Fargate, Lambda의 비용을 줄이는 방법에 대해 알아보겠습니다. The post Reserved Instance & Savings Plan appeared first on NDS Cloud Tech Blog.
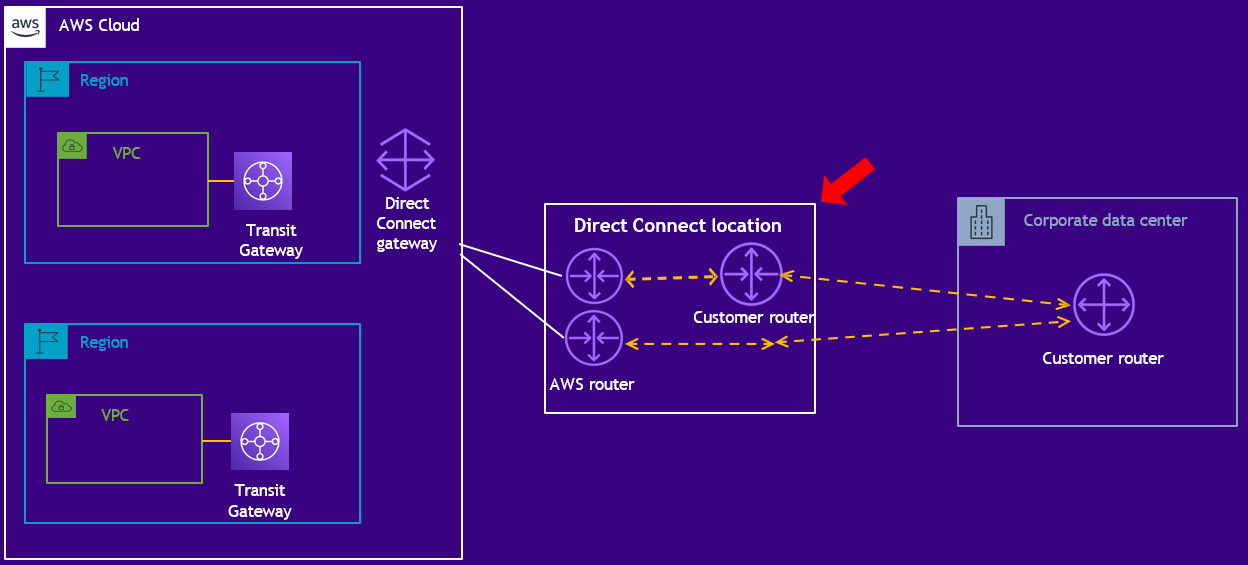
이번 블로그에서는 AWS Direct Connect의 개념, 구성 요소, 작동 방식, 주요 활용 사례를 알아보겠습니다. The post AWS Direct Connect(DX): 클라우드와 온프레미스를 연결하는 최적의 네트워크 솔루션 appeared first on NDS Cloud Tech Blog.
이 전망은 삼성SDS 마케팅팀 MI그룹에서 2024년 말에 400여 명의 국내 IT 의사결정 관계자를 대상으로 실시한 설문 결과로서, 2025년도에 직면할 국내기업의 경영 환경과 IT 투자 전망 중 제조산업을 집중 분석하였습니다.

안녕하세요. 올리브영에서 iOS 개발을 맡고 있는 럭셔Lee입니다. Let'Swift 2024 컨퍼런스에서 올리브영 부스를 운영하며 많은 iOS…

스마트폰을 바꾼 후 이전에 썼던 기기를 중고로 팔아보신 적 있으세요? ‘이 정도 상태의 기기면 어느 정도 가격대가 적당한 거지?’ 고민하며, 수많은 중고 매물 게시글을 일일이 확인하지는 않으셨나요? 이제는 LLM(대형 언어 모델) 덕분에 이렇게 번거롭고 어려웠던 작업이 훨씬 쉽고 빠르게 해결되고 있어요.이 글에서는 LLM을 활용해 중고거래 게시글에서 스마트폰 정보를 추출하고, 이를 통해 시세를 산출한 방법을 소개하려고 해요. 먼저 스마트폰 시세조회 서비스를 왜 만들게 됐는지 배경을 간단히 살펴본 후, LLM으로 게시글을 분류·정제하는 과정, BigQuery를 이용해 정보를 후처리하고 시세를 집계하는 과정, 마지막으로 벡터 DB 기반으로 유사 게시글을 추천하는 과정을 단계별로 소개해 드릴게요. LLM으로 사용자 경험을 효과적으로 개선할 방법을 고민 중인 분들에게 이 사례가 큰 도움이 되면 좋겠어요.스마트폰 시세조회 서비스의 모습스마트폰 시세조회는 왜 필요할까요?많은 중고거래 판매자들이 물품의 적절한 가격을 결정하는 걸 어려워해요. 개인 간 거래는 워낙 다양한 상품이 혼재되어 있기 때문인데요. 종류도 워낙 다양한데 상태도 가지각색이라, 물품의 정확한 시세를 한눈에 파악하기 어려운 거죠. 스마트폰을 예로 들면 단순히 같은 기종만 검색해서 끝날 일이 아니라, 사용 기간, 배터리 효율, 스크래치 여부 등 상태가 비슷한 기기가 얼마에 팔리는지 일일이 확인해야 하는 거예요.중고거래팀은 사용자가 물품의 시세를 한눈에 확인하고 더 쉽게 가격을 결정할 수 있도록, 아이폰, 갤럭시 기종을 대상으로 한 스마트폰 시세 조회 서비스를 테스트하기로 했어요. 다양한 물품 중 스마트폰을 베타 테스트 대상으로 선정한 이유는 다음과 같아요. 스마트폰은 제품 모델이 명확하고 게시글 수가 많아 데이터 기반 시세 계산에 유리해요. 또 판매 단가가 높아 가격 결정이 중요한 상품이기도 하고요.결과적으로 모델, 용량, 새 상품 여부, 스크래치 및 파손, 배터리 효율 등 구체적인 물품 상태에 따라 시세가 어느 정도인지 파악할 수 있는 서비스를 만들었어요. 예를 들어 사용자가 ‘아이폰 16 Pro 128GB’를 선택하고 필터에서 구체적인 ‘사용 상태’나 ‘배터리 성능’을 설정하면, 곧바로 그에 따른 시세 정보를 ‘OOO만원-OOO만원’과 같은 가격 범위의 형태로 확인할 수 있어요. 이번 프로젝트는 머신러닝을 활용해 당근 중고거래 데이터를 기반으로 정확한 시세를 제공한 첫 번째 시도로, 팀 내에서도 의미가 큰 프로젝트이기도 했는데요. 그럼 본격적으로 기능을 구현해 나간 과정을 단계별로 소개해 드릴게요.Step 1. 상품 정보 추출가장 큰 문제는 게시글에서 상품 정보를 추출하는 것이에요. 당근은 판매자의 글쓰기 허들을 낮추기 위해 중고거래 게시글에 구체적인 기종이나 물품 상태를 입력하도록 요구하지 않아요. 하지만 구체적인 물품 상태별로 스마트폰 시세를 제공하려면 모델, 용량, 새 상품 여부, 스크래치 및 파손 여부, 배터리 효율 등 여러 가지 다양한 조건을 알아내야 했어요.기존에는 이런 데이터를 추출하려면 복잡한 정규식을 만들거나 이에 특화된 ML 모델을 만들어야 했어요. 하지만 LLM을 도입하여 ‘모델명’, ‘용량’, ‘스크래치 여부’ 등을 추출할 수 있게 되었어요. 정규식이나 별도 모델을 구축할 때와 달리, 프롬프트 수정만으로도 추출 정확도를 높일 수 있어 공수가 매우 줄었어요.게시글에서 정보를 추출하는 과정 예시우선 타겟 게시글들을 정한 후 프롬프트 엔지니어링을 통해 결과물을 뽑았어요. 그 결과물을 채점하고 프롬프트를 수정하여 추출의 정확도를 높였어요. 만족할만한 성능이 나온 후에는 게시글이 생성될 때마다 LLM을 적용하여 사내 데이터 웨어하우스인 BigQuery에 적재하는 파이프라인을 구축했어요.BigQuery에 적재한 이후에는 데이터의 후처리를 거쳤어요. LLM 특성상 잘못된 분류를 하거나 허구의 정보를 생성하는 환각 문제를 완전히 피할 수는 없었어요. 특히 모델명을 추출하는 과정에서 나열한 기종 이외에 다른 이름으로 추출한다거나, 복잡한 기종 명의 경우 잘못된 이름으로 추출하는 경우도 있었어요.예를 들어, 1세대 갤럭시 폴드의 경우 “Galaxy Fold”지만 2세대부터는 “Galaxy Z Fold2”라는 이름을 가져요. 하지만 LLM은 “Galaxy Z Fold”나 “Galaxy Fold1”, “Galaxy Fold 1”처럼 사용자의 입력한 잘못된 모델명을 그대로 추출하는 경우가 있었어요.결국 프롬프트에서 모든 예외 케이스를 처리하기보다는, BigQuery View Table을 통해 2차 가공을 하기로 했어요. 아래 코드는 특정 스마트폰 시리즈(예: Galaxy Fold, Galaxy Flip 등)의 여러 가지 잘못된 표기를 정규화하는 SQL 예시예요. 이 로직을 만들 때도 GPT를 활용해 삽질 과정을 크게 줄였어요.-- Galaxy Fold 패턴 처리WHEN REGEXP_CONTAINS( REGEXP_REPLACE(REGEXP_REPLACE(item_name, r'\\s5G$', ''), r'(?i)(\\+|plus)', '+'), r'^Galaxy\\sFold($|\\s?\\d+)' ) THEN CASEWHEN REGEXP_CONTAINS( REGEXP_REPLACE(REGEXP_REPLACE(item_name, r'\\s5G$', ''), r'(?i)(\\+|plus)', '+'), r'^Galaxy\\sFold($|\\s?1)$' ) THEN 'Galaxy Fold'ELSE REGEXP_REPLACE( REGEXP_REPLACE( REGEXP_REPLACE(item_name, r'\\s5G$', ''), r'(?i)(\\+|plus)', '+' ), r'Galaxy\\sFold\\s?(\\d+)', 'Galaxy Z Fold\\\\1' )-- ...Step 2. 데이터 기반 시세 집계위 과정을 통해 정제된 모델명과 흠집, 배터리 용량 등에 대한 원시 데이터를 얻었어요. 이제 이 데이터들을 집계해서 시세 정보를 만들어낼 수 있어요. 데이터를 집계하고, 사용자분들에게 제공하는 데에는 BigQuery와 MySQL, 두 개의 저장소를 사용했어요. 각 저장소의 장단점이 다르다 보니 각각의 장점을 활용해 더 좋은 서비스를 만들어내기 위해서였어요. 두 저장소의 특징을 비교해 보면 다음과 같아요.MySQL주요 용도: 트랜잭션 처리(OLTP), CRUD 작업, 실시간 데이터 제공 및 웹 백엔드성능 특성: 낮은 지연 시간과 빠른 트랜잭션 처리로 실시간 응답에 유리데이터 이동 및 적재 전략: 사용자에게 빠른 응답을 위한 최종 집계 결과나 가공된 데이터 저장에 적합사용 사례: 웹 애플리케이션 백엔드, 실시간 거래 처리BigQuery주요 용도: 대규모 데이터 분석(OLAP), 데이터 웨어하우징, 로그/이벤트 분석성능 특성: 대규모 집계 및 복잡한 분석 쿼리에 최적화데이터 이동 및 적재 전략: 원본 대용량 데이터 분석에 집중, 불필요한 데이터 이동 최소화사용 사례: 데이터 사이언스, 머신러닝, 대규모 로그 분석, 배치 분석두 저장소의 장점을 얻기 위해 팀에서 사용한 방법은 다음과 같아요. 우선 빅쿼리에서 주간 시세조회 처리 같은 대용량 작업을 마친 후, 집계 결과만을 MySQL로 옮겨 저장했어요. 그 후 사용자가 화면에 진입할 때는 BigQuery 접근 없이 MySQL을 활용해서 시세조회 결과를 내려줬어요.BigQuery에서 MySQL로 모든 데이터를 덤프했다면, 비효율이 발생했거나 응답시간이 느려졌을 텐데요. 이 과정을 통해 그런 문제들을 방지할 수 있었어요. 또한 집계 결과를 BigQuery에서 MySQL로 옮겨오는 작업을 멱등하게 설계하여서 운영의 편의성을 높였어요.Step 3. 유사 게시글 제공이 과정을 통해 사용자가 원하는 조건의 상품 시세를 구체적인 가격 범위로 제공하게 됐어요. 그런데 당근에서 물건을 팔기 전 비슷한 물건을 하나하나 확인해 보는 것처럼, 일부 사용자의 경우 좀 더 정확한 가격 책정을 위해 다른 게시글을 직접 확인하고 싶어 할 수도 있겠다고 판단했어요. 이 과정을 편리하게 만들기 위해 시세 조회 화면에서 시세 통계 데이터뿐만 아니라 유사 게시글도 제공하려 했어요. 이 기능은 통계 데이터와는 다르게 게시글의 임베딩을 활용해 구현했어요.임베딩은 텍스트, 이미지 등의 개체를 수학적인 형태로 바꾸어 표현한 것이에요. 좋은 임베딩 모델은 텍스트의 의미를 수학적으로 잘 변환하기 때문에, 의미상으로 유사한 게시글을 빠르게 찾아낼 수 있어요. 예를 들어 영어로 작성한 “iPhone”과 한글로 적은 “아이폰”이 같은 의미라는 것은 단순히 문자열의 유사도로는 알아낼 수 없어요. 하지만 좋은 임베딩 모델을 사용한다면 이 두 단어는 비슷한 벡터로 변환이 되고, 따라서 사용자가 “아이폰”으로 검색하든 “iPhone”으로 검색하든 동일한 결과를 제공할 수 있게 돼요. 또 팀에서는 벡터 저장과 검색에 최적화된 데이터베이스인 벡터 DB, 그중 Pinecone을 도입해서 벡터 서빙을 최적화했어요.그 과정이 순탄하지만은 않았는데요. 쿼리와 문서의 불일치 때문에 어려움을 겪었어요. 당근의 게시글은 제목이나 본문이 모두 길고 상세하게 설명하는 형태예요. 하지만 스마트폰 시세조회의 경우 “아이폰 16 프로 흠집 있음”처럼 아주 짧은 단어로 이루어진 형태인데요. 이러다 보니 생각보다 유사하지 않은 게시글들이 검색되는 경우가 잦았어요.문제 해결을 위해 여러 가지 임베딩 모델을 테스트해 보다가 구글의 임베딩 모델은 작업 유형을 선택할 수 있다는 걸 알게 되었어요. 임베딩 모델을 호출할 때 문서의 경우 task_type: RETRIEVAL_DOCUMENT, 쿼리의 경우 task_type: RETRIEVAL_QUERY과 같은 형태로 옵션을 넘겨 해당 작업에 최적화된 형태로 임베딩을 만들어냈어요.위 옵션을 지정하고 다른 임베딩 모델들과 비교하자 훨씬 좋은 결과를 얻었어요. 임베딩의 평가는 해당 임베딩 모델을 통해 얻어낸 게시글이 추출 모델, 메타데이터 (흠집 유무, 배터리 사이클 등)에 맞을 때마다 더 높은 점수를 부여하는 방식으로 설계했어요. 이 채점 과정 또한 LLM을 통해 자동화하여 공수를 많이 줄였어요.유사한 게시글들을 잘 찾아내지만, 순서가 생각과 잘 맞지 않는 문제도 있었어요. “갤럭시 S24”를 검색했는데 15개의 게시글 중 갤럭시 S24가 10개, S24+가 3개, S23이 2개 있다고 생각해 보세요. 그러면 우리가 기대하는 결과는 S24, S24+, S23 순으로 게시글이 나열되는 거예요. 하지만 모두 높은 유사도를 보이다 보니 순서가 뒤죽박죽이었어요.RAG나 추천 등에 익숙하신 분이라면 ReRanker를 도입해서 문제를 풀면 될 거 같다는 생각이 드실 거예요. 저희도 ReRanker를 테스트해 보았는데, 파인튜닝 같이 도메인에 특화하지 않은 상태로 일반 모델을 적용했을 때는 딱히 더 나은 결과를 얻지 못했어요. 게다가 팀에는 이 과정을 도와줄 수 있는 ML 엔지니어도 없는 상황이어서 저희는 다른 방법을 택하기로 했어요.이미 유사한 게시글을 들고 온 이후기 때문에, 특정 규칙을 기반으로 어떤 문서들은 배제하고 사용했어요. 예를 들어 “탭”, “패드” 같은 단어 등장한 게시글은 사용하지 않는 식이죠. 같은 맥락으로 내 아이템과 일치하는 단어가 많을수록 더 상위에 위치시키고, 일치하지 않는 단어가 있을 경우 순위를 좀 더 아래로 조정했어요. 이 과정에서 기본적인 동의어 처리도 진행했고요. 예를 들어, 갤럭시 S23의 시세를 조회한다면 갤럭시의 동의어인 Galaxy S23이 있는 게시글은 상위에 위치시키고, S23 울트라는 울트라로 인해 감점되어서 더 아래로 내려가는 식이죠.마치며여태까지 LLM과 임베딩 모델 등 새로운 기술을 활용하여 당근의 자체 데이터 기반으로 시세 조회 기능을 만들어간 과정을 소개해 드렸어요. 그동안은 없었던 새로운 도구를 활용하여 사용자의 문제를 풀어나가 기술적으로도, 한 사람의 메이커로서도 즐거운 경험이었어요.이 과정에서 얻은 교훈은 다음과 같아요.LLM이 똑똑하고 좋은 도구는 맞지만, 모든 과정을 프롬프트 엔지니어링으로 해결하려고 하기보다는 후처리 과정을 따로 작성하는 게 더 효율적일 때도 있다는 것내가 필요한 장점을 가진 저장소를 선택하면 효율적으로 일할 수 있다는 것내 작업 유형에 잘 맞는 임베딩 모델을 사용하면 문제를 쉽게 풀어낼 수 있다는 것중고거래실은 이처럼 새로운 도구를 활용하여 사용자들의 문제를 풀고 더 좋은 경험을 제공하는 것에 진심인 팀이에요. 팀에 흥미가 생기셨다면 아래 공고를 통해 지원하실 수 있어요.Software Engineer, Backend — 중고거래LLM을 활용한 스마트폰 시세 조회 서비스 구축 was originally published in 당근 테크 블로그 on Medium, where people are continuing the conversation by highlighting and responding to this story.

몇 년 전 JetBrains는 Kotlin Multiplatform IDE를 만들어 KMP 애플리케이션의 개발을 지원하자는 구상에 착수했습니다. Fleet 플랫폼 기반으로 제작하며 독립적인 IDE를 출시할 의도로 이 모험을 시작했습니다. 그런데 이 기간 동안 특히 KMP를 사용하는 고객으로부터 IntelliJ Platform의 기능과 지원이 KMP용으...

지난 2월 20일에 열린 AWS Developer Day 2025 현장에서는 책임 있는 생성형 AI를 개발 워크플로에 통합하는 방법을 선보였습니다. 이 이벤트에서는 Generative AI Applications and Developer Experience의 Director Srini Iragavarapu, AWS Evangelism의 VP Jeff ...
이 전망은 삼성SDS 마케팅팀 MI그룹에서 2024년 말에 400여 명의 국내 IT 의사결정 관계자를 대상으로 실시한 설문 결과로서, 2025년도에 직면할 국내기업의 경영 환경과 IT 투자 전망 중 금융산업을 집중 분석하였습니다.

글로벌 출판사와 총 10억 원대 판권 계약을 맺으며, 작품성과 글로벌 흥행성을 입증했다. The post 리디, 오리지널 소설 ‘식물, 상점’ 해외 9개국 판권 수출 appeared first on 리디주식회사 RIDI Corporation.
![[행사스케치] 사우디 LEAP 2025, 팀네이버 기술을 널리 알렸습니다.](https://blogthumb.pstatic.net/MjAyNTAyMjRfMzIg/MDAxNzQwMzg5MTU4Mzc0.L-bJCreLDxUjigKoQ0mX-xQtyV1ggTc890wWavVsHJMg.tc7AEPa-enCzdwB8-N5qjYXxg9AF1W5g7BqNOZVsfP0g.PNG/leap_thumb.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com 입니다. 얼마 전 팀네이버가 사우디에서 열리는 글로벌 기술 전시 행사 LEAP 2025에 2년 연속 참석한다는 소식을 전해드렸죠. 네이버 기술 전반을 소개한 작년에 이어 올해는 사우디의 디지털 문화 유산을 지키는 AI 기술 개발 협력 방향을 제안했습니다. 더불어 사우디 자치행...
![[술술 읽히는 업무 해설집-근태편] 특별 휴가로 직원 만족도 끌어 올리기](https://blogthumb.pstatic.net/MjAyNTAyMjRfMjEw/MDAxNzQwMzc3MzkwMDc1.hecRFS9EwBO-j2wQboutkEmh6q2y8ph6rvl9AXiXxAsg.nN2M8vq7WFClihgBQZpDXavfHV1QrLOm1y_9KCh_YTUg.JPEG/네블_썸네일.jpg?type=s3)
안녕하세요, 협업과 소통을 위한 필수 기능으로 글로벌 53만 기업의 든든한 협업툴 역할을 해온 네이버웍스(NAVER WORKS)입니다! "업무와 관련된 것이라면 뭐든지 쉽게 풀어드립니다!" 술술 읽히는 업무 해설집 회사의 성장에 있어서 구성원의 사기는 매우 중요한 요소인데요. 구성원의 사기 진작에 기여할 수 있는 방법이 바로 ‘휴가’입니다. 그러나 휴...
이 전망은 삼성SDS 마케팅팀 MI그룹에서 2024년 말에 400여 명의 국내 IT 의사결정 관계자를 대상으로 실시한 설문 결과로서, 2025년도에 직면할 국내기업의 경영 환경과 IT 투자 전망에 대해 분석하였습니다.
![[캘린더️] 3월 무료 교육 웨비나 일정 모음](https://blogthumb.pstatic.net/MjAyNTAyMTdfMTY4/MDAxNzM5Nzg3OTIwODA2.hEFVGNhs-2MUjsgYMsCU7dipxY_OaXymMXqSJi3SOFAg.DD6wDRAeM7sC-MhBHk28UPYhAyms9Vnqeb19EOY0A6wg.PNG/3월_교육_썸네일.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com 입니다.
![[웹툰파헤치기] 치명적 로맨스…’괴물 아가씨와 성기사’](https://static.teamblind.com/img/cppc/upload_5ab60103.jpeg)
The post [웹툰파헤치기] 치명적 로맨스…’괴물 아가씨와 성기사’ appeared first on 리디주식회사 RIDI Corporation.

YouTrack 2025.1 릴리스에는 프로젝트와 작업을 더욱 빠르게 탐색하는 데 도움을 주는 대담한 새 디자인이 도입되었습니다. 이 새로운 모양과 느낌은 팀이 프로젝트를 수행하는 방식에서 얻은 통찰력을 바탕으로 합니다. 새로운 디자인에는 다음과 같은 부분이 도입되었습니다. 매일 수십만에 달하는 팀이 YouTrack을 통해 비즈니스를 이끌어가고 있습니...

[2월 셋째주] 알약 스미싱 알림 본 포스트는 알약M 사용자 분들이 '신고하기' 기능을 통해 알약으로 신고해 주신 스미싱 내역 중 '특이 문자'를 ...

안녕하세요! 검색플랫폼팀 테디예요. 당근 검색플랫폼팀은 사용자에게 보다 나은 검색 경험을 제공할 수 있도록 튼튼한 플랫폼을 만드는 팀이에요. 검색 서비스와 인프라를 운영 및 관리하면서 검색 트래픽을 안정적으로 소화할 수 있도록 만들죠.이를 위해 팀에서 다양한 노력을 하고 있는데요. 최근에는 검색 형태소 분석 사전 배포 과정을 개선하는 프로젝트를 진행했어요. 그래서 오늘은 프로젝트를 진행하게 된 계기와 과정, 그리고 결과를 간략하게 공유드려 볼게요.📚 형태소 분석을 위한 기본 사전검색에서 형태소 분석 기능은 필수예요. 이 기능은 주로 문서를 검색하거나 색인할 때, 검색어 또는 문서의 검색 대상 필드(제목, 본문 등)의 형태소를 분석하기 위해 사용돼요.저희 팀은 Elasticsearch를 검색 엔진으로 사용하면서 Nori를 기반으로 자체 구축한 Analysis-Karrot 플러그인을 통해 형태소를 분석하고 있어요. 이 플러그인은 내부에 가지고 있는 기본 사전 (또는 시스템 사전)을 기반으로 형태소를 분석해요. 해당 사전은 한국어 단어들의 품사, 형태, 가중치 등 형태소 분석에 사용되는 다양한 정보를 가지고 있어요.내부 사전 데이터 일부형태소를 잘 분석하고 나아가 검색 품질을 향상하기 위해서는 이 기본 사전을 잘 관리하는 것이 매우 중요해요. 왜냐하면 줄임말, 신조어 등이 계속해서 생겨나고, 어떤 단어라도 검색어로 들어올 수 있기 때문이에요. 이러한 변화에 잘 대응하기 위해 기본 사전 내용을 주기적으로 업데이트하며 고도화해야 해요.⚙️ 기본 사전 업데이트 프로세스AS-IS: 기본 사전 업데이트 프로세스현재 기본 사전 내용을 업데이트하는 과정은 아래와 같아요.검색 어드민을 통해서 새로운 사전 데이터를 사전 DB에 추가한다.사전 DB를 읽어서 새로운 사전 데이터 셋을 생성한다.사전 데이터 셋을 주입하여 Analysis-Karrot 플러그인을 생성한다.Analysis-Karrot 플러그인을 Elasticsearch 검색 클러스터에 재배포한다.여기서 문제는 ES 검색 클러스터 배포는 매우 신중해야 하는 무거운 작업이라는 점이에요. 만약 검색 클러스터 배포 과정에서 문제가 발생한다면 검색 기능 자체를 사용하지 못할 수도 있어요. (SPOF) 그래서 설정 변경 또는 버전 업데이트 등과 같이 검색 클러스터 운영에 필수적인 상황을 제외하고는 배포를 최소화하는 것이 운영 측면에서 지향하는 방향이에요. (DB 운영과 비슷하다고 볼 수 있죠.)🤔 검색 클러스터 배포 없이 사전 업데이트 가능할까?팀에서는 검색 클러스터 배포를 하지 않고 기본 사전을 업데이트할 수 있는 방법이 없을까 고민하면서, 기본 사전을 사용하는 플러그인 내부 코드를 분석했어요.Nori를 기반으로 자체 개발한 Analysis-Karrot ES 플러그인은 내부적으로 Lucene의 BinaryDictionary를 사용해요. 이를 통해 플러그인 내부에 들어있는 불변하는 성격의 사전 데이터를 싱글톤 객체를 사용해서 메모리에 로드하고 있어요. 여기서 저희는 Dictionary 객체를 생성할 때 플러그인 내부에 있는 사전 데이터가 아니라 외부에 저장한 사전 데이터를 참조할 수 있도록 변경하면 어떨까 생각했어요.BinaryDictionary 를 구현해서 만든 TokenInfoDictionary 클래스 명세 예시. 싱글톤으로 구현되어 있다. (코드 보기)💡 아이디어를 구현해 보자! (a.k.a PoC)TO-BE: 기본 사전 업데이트 프로세스위에는 아이디어를 조금 더 구체화하기 위해 그림으로 표현해 본 모습이에요. 기존에는 플러그인을 새로 만들어서 Elasticsearch 도커 이미지에 적용 및 배포를 진행했다면, 새로운 방식에서는 아래와 같은 단계로 새로운 사전을 배포하게 돼요.사전 데이터(*.dat)를 빌드 후 S3에 업로드한다.업로드된 사전 데이터를 검색 엔진 노드의 로컬 파일 시스템에 저장한다.인덱스를 생성할 때 설정에서 사전 데이터가 저장되어 있는 경로를 지정한다.형태소 분석 시 지정된 경로에 있는 사전으로 토크나이저 객체를 생성 및 사용한다.이 아이디어를 구현하기 위해 많은 요소들을 고려해야 했는데요. 그중 가장 핵심적인 부분은 기존에 싱글톤 패턴으로 오직 플러그인 내부에 저장된 사전만 로드해서 사용하던 사전 관련 로직을, 로컬 파일 시스템에 저장된 여러 개의 사전을 경로 기준으로 각각 로드해서 사용할 수 있도록 수정하는 부분이었어요. 아래는 싱글톤 인터페이스의 변경 예시예요.싱글톤 패턴으로 사용하던 사전 로직을 경로 기준으로 여러 개의 사전을 읽을 수 있게 수정한 코드 인터페이스 일부🫠 실패 그리고 원인 분석그러나 안타깝게도 저희 팀은 두 달 넘게 구현 및 단위 테스트를 진행한 이후 통합 테스트를 진행하는 과정에서 문제를 발견했어요. 크고 작은 문제들 중에서 가장 중요했던 건 힙 메모리 사용량이 30% 이상 증가했다는 점이었어요.Elasticsearch에서는 힙 메모리 사용량이 75% 이상이면 매우 주의를 요하며 적절한 최적화를 권유해요. 85% 이상이면 클러스터 퍼포먼스가 저하되고 circuit breaker 에러가 발생할 수 있다고 말하죠. 특히 운영 클러스터에서 circuit breaker 에러가 발생하면, 해당 노드가 일시적으로 중단 또는 재시작되면서 클러스터에 이상 현상을 발생시킬 수 있어요. 매우 조심해야 하는 거죠.PoC 전후 비교 결과 (왼쪽: 전, 오른쪽: 후)결국 PoC를 중단하고 힙 덤프를 통해 힙 사용량 증가에 대한 원인 파악에 나섰어요. 가장 눈에 띄는 문제는 Byte Array 크기 증가였어요. (2.26GB to 7.16GB) 이건 곧 사전 데이터 크기가 증가했다는 뜻이에요. 기존에는 싱글톤 패턴을 사용해서 단일 인스턴스로 사전을 생성하여 서빙했지만, 여러 버전의 사전을 서빙하기 위해 싱글톤 패턴을 제거했는데요. 이로 인해 힙 메모리가 증가할 거라고 어느 정도 예상하긴 했어도, 이렇게까지 많이 증가할 줄은 미처 몰랐어요.Heap Dump 결과 분석왜 Byte Array 크기가 증가했는지 파악하기 위해 계속해서 디버깅을 진행했어요. 그러다 Elasticsearch 코드에서 몰랐던 사실 하나를 발견했어요. 그것은 인덱스 스키마 설정에 Tokenizer를 선언하면 Tokenizer 객체를 생성하면서 내부적으로 기본 사전을 호출한다는 점이었어요. 저희는 인덱스 스키마에는 두 개의 Tokenizer를 정의하고 있었기 때문에, 인덱스를 생성할 때 기존 대비 최소 두 배 이상의 힙 메모리를 사용하게 된 거였어요.PUT my-index-000001{ "settings": { "analysis": { "analyzer": { "my_custom_analyzer": { "type": "custom", "tokenizer": "...", // Tokenizer 선언 예시 ... }...💪 재시도!실패에서 배운 점들을 교훈 삼아 두 번째 PoC를 진행하게 됐어요. 이번에는 레슨런을 바탕으로 두 가지 목표를 세우고 작업을 시작했어요.1) 사용하지 않는 사전 데이터를 제거하여 힙 사용량을 최적화하자저희가 사용하고 있는 플러그인은 Nori를 기반으로 만들어졌기 때문에 직접 구축한 사전 외에도 기본적으로 Nori가 가지고 있는 다양한 종류의 사전을 가지고 있어요. 또한 사전 스키마에도 12가지의 정보가 들어있고요. 여기서 사용하지 않는 데이터를 최대한 제거함으로써 플러그인을 경량화시키고 나아가 힙 메모리 사용량을 줄이고자 했어요. 결과적으로 이 과정을 통해 플러그인 크기를 33MB에서 7MB로 줄이게 됐어요.플러그인의 크기를 과거 33MB에서 7MB까지 감소2) 최대 2개의 최신 사전 데이터만 힙 메모리에 로드하자예시) 시간 순서(왼쪽에서 오른쪽)에 따라 달라지는 사전 업로드 상태앞선 실패로 얻은 교훈 중 하나는 “사전을 버전별로 유일하게 관리해서 같은 버전을 사용할 때 객체 참조가 가능하게 하자”라는 것이었어요. 워낙 빈번하게 객체 참조가 일어나기 때문에 참조할 때마다 새로운 객체를 만들게 되면 힙 메모리 사용량이 금방 100%에 도달하거든요. 그래서 이번에는 버전별 사전 관리를 위해 Map<Version, Dictionary>를 만들고 이 Map을 관리하는 매니저 객체를 싱글톤 패턴으로 구현했어요.싱글톤 패턴으로 사용하던 사전 로직을 매니저 인스턴스를 호출하도록 수정한 코드 인터페이스 일부🚀 배포 및 모니터링여러 번의 크고 작은 테스트를 거치면서 로직을 검증할 시간을 충분히 가졌고, 그 결과 프로덕션 환경에 배포해도 되겠다는 결론을 내렸어요. 그래서 중고거래 클러스터에 해당 기능을 배포했어요. 현재는 사전을 직접 운영 및 관리하고 있는 검색 운영팀에서 기본 사전 업데이트가 필요할 때마다 사전을 배포해 주고 계세요. 저희 팀은 함께 모니터링을 하고 있고요. 이로써 한 달에 한 번씩 몰아서 반영했던 사전 업데이트를 하루에 한 번씩 할 수 있게 되면서, 보다 빠르게 사용자 검색 경험을 개선할 수 있는 기반을 마련했어요.기본 사전 배포 이후 검색실 내부 반응🤔 앞으로 더 해야 할 일은?물론 아직 몇 가지 추가로 해야 할 일들이 남아있어요. 대표적으로는 프로덕션 환경이 다른 클러스터에도 점진적으로 배포해 나가는 일이 남아있어요. 또한 사전 업데이트 알람 추가나 모니터링 대시보드 고도화, 그리고 사전 업데이트 실패에 대한 Fallback 구성 등 안정성 및 가용성 측면의 작업들도 계속해서 진행할 예정이에요.🥕 함께 해요!당근 검색 플랫폼팀은 당근 검색 사용자들의 검색 경험 개선을 위해 앞으로도 빠른 피드백 루프를 바탕으로 플랫폼을 끊임없이 고도화해 나갈 거예요. 또한 검색의 방대한 트래픽을 무리 없이 소화하고 보다 나은 검색 결과를 제공할 수 있는 튼튼한 플랫폼을 만들기 위해 꾸준히 노력할 거예요.이러한 저희의 눈부신 여정에 함께하실 분들을 찾고 있어요. 많은 관심 부탁드려요!https://about.daangn.com/jobs/5688517003/읽어주셔서 감사해요!검색 형태소 분석 사전 배포 과정 개선하기 was originally published in 당근 테크 블로그 on Medium, where people are continuing the conversation by highlighting and responding to this story.

한층 깊어진 스토리와 본격적인 로맨스가 전개될 예정이다. The post 리디, 인기 웹툰 ‘상류 사회’ 시즌2 연재 실시 appeared first on 리디주식회사 RIDI Corporation.

안녕하세요! 2025년에도 고객 여러분의 비즈니스가 성공하실 수 있도록 AWS가 늘 함께하도록 하겠습니다. 예년과 같이 작년 한 해에 AWS 클라우드를 통해 빠른 민첩성과 비용 절감으로 기존 서비스를 혁신한 다양한 고객 사례를 모아보았습니다. 대기업, 중소 기업 뿐만 아니라 소프트웨어 개발 기업과 스타트업에 이르기까지 다양한 고객들이 어떻게 AWS를 ...
![[이스트소프트x이스트시큐리티] ‘파트너 킥오프 2025’ 성료 소식!](https://blog.kakaocdn.net/dn/HHVy1/btsMmcM8Npt/wGV1SeJpLKyqMcRTW984E0/img.png)
안녕하세요, 이스트시큐리티입니다. 지난 2월 14일, ‘이스트 파트너 킥오프(Kick-Off) 2025’ 행사가 성황리에 마무리되었습니다. 이번 행사에서는 이스트소프트 및 이스트시큐리티의 주요 파트너사 고객 120여 명이 참석해 자리를 빛내 주셨습니다. 파트너 킥오프 2025, 어떤 행사였을까...

사내 데이터 디스커버리 도구인 데이터카탈로그는 DataHub를 기반으로 구축되었습니다. DataHub는 다양한 플랫폼과 연동되는 활발한 오픈소스 프로젝트로, 필요한 기능들을 새로 개발하지 않고도 활용할 수 있다는 장점이 있습니다. 그러나 DataHub를 처음 도입했을 때, 사내 구성원들로부터 UI/UX가 불편하다는 피드백을 받았습니다. 특히 데이터에 익숙하지 않은 사용자들에게는 DataHub의 다양한 기능들이 오히려 진입 장벽이 되었습니다. 저희는 사용자들이 원하는 데이터를 쉽게 찾고 활용하는 […] The post 데이터카탈로그에서 DataHub를 이용하는 방법 first appeared on 우아한형제들 기술블로그.