
AWS KOREA
Amazon EC2 M8i 및 M8i Flex 범용 인스턴스 정식 출시
Else
오늘 Amazon Elastic Compute Cloud(Amazon EC2) 범용 M8i 및 M8i-Flex 인스턴스의 정식 출시를 발표합니다. 이는 지속적인 올코어 3.9GHz 터보 주파수로 AWS에서만 사용할 수 있는 사용자 지정 Intel Xeon 6 프로세서 기반 인스턴스입니다. 이러한 인스턴스는 동급 Intel 프로세서 중 가장 뛰어난 성능...
2025-08-29




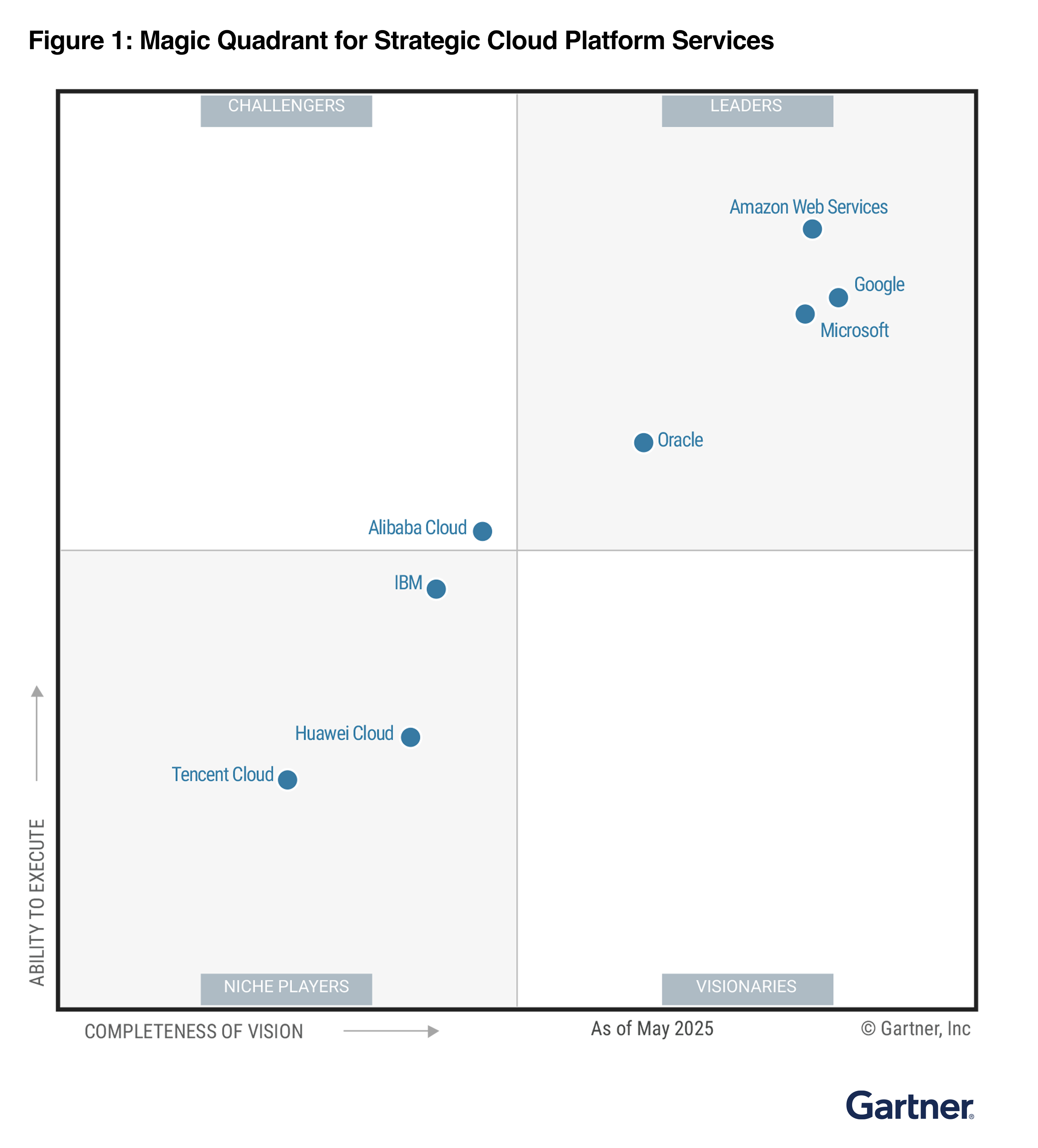











.png)


![[중기부에서알려드립니다.]2차버팀목자금 플러스 지원 대상자입니다. 절차 확인바랍니다. hxxp://is[.]gd/m****ea](https://blog.kakaocdn.net/dn/bi1z4u/btsNFnUUgbd/g20OLSTmpdzmZfdNx3Zklk/img.png)


![[행사 스케치] 대한민국을 이끄는 방송국과 함께 네이버클라우드 데이터센터 각 투어](https://blogthumb.pstatic.net/MjAyNTA0MzBfMTg2/MDAxNzQ1OTc2MTg1MjM2.lQSG1hQ1-gmDxpLUsLXtcJXWI5ORgE0MXeLV_u_W5K4g.eDZAM3MOkQR2Us3JJ3AEOfJY-Yk3go7oDOzPFoH6KEog.PNG/250430_%C7%D1%B1%B9%B9%E6%BC%DB%B1%E2%BC%FA%C0%CE%BF%AC%C7%D5%C8%B8.png?type=s3)