라인
코드 품질 개선 기법 2편: 확인 여부를 확인했나요?
Else
안녕하세요. 커뮤니케이션 앱 LINE의 모바일 클라이언트를 개발하고 있는 Ishikawa입니다. 저희 회사는 높은 개발 생산성을 유지하기 위해 코드 품질 및 개발 문화 개선에 힘쓰...
2025-01-08
국내 IT 기업들의 기술 블로그 글을 한 곳에서 모아보세요
안녕하세요. 커뮤니케이션 앱 LINE의 모바일 클라이언트를 개발하고 있는 Ishikawa입니다. 저희 회사는 높은 개발 생산성을 유지하기 위해 코드 품질 및 개발 문화 개선에 힘쓰...
![[네이버클라우드캠프] 2024 특별 커리어 성장 세미나 <커리어, 함께 Carry On> 현장 스케치](https://blogthumb.pstatic.net/MjAyNTAxMDdfMTQ5/MDAxNzM2MjE0OTMyODI5.dD_3udVcPDYsxNfXDEUsLEzjnmDBkLzaTzStrMacPZAg.t0g1ujWyunA3uDNeUAqaZCAPLDGUMaWolLhz3uoC1zog.PNG/thumb.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com입니다. #네이버클라우드 #네이버클라우드캠프#네클캠 #K-Digital Training #KDT #Together We Rise #성장 세미나 #성장세미나 지난 12월 11일 수요일, 네이버클라우드캠프 2024 특별 커리어 성장세미나 K-Digital Training 과정 설명...

stockcake.com안녕하세요. 29CM 모바일팀 iOS 개발자 김중원입니다. 이번 글에서는 앱 시작 시간을 개선하기 위해 새 기술을 도입하고 이를 정량적으로 평가하기 위한 인프라를 구축하여 명확한 성과를 확인한 내용을 공유드립니다.29CM 모바일 앱은 높은 수준의 성능 유지를 목표로 성능 지표 설정과 정량적 측정을 위해 2분기 과제로 앱 성능 측...

This article is the last in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Need ...
![[프로그램] CSAP 인증 기업 이용 1위! 네이버클라우드가 준비한 공공 SaaS 지원 프로그램](https://blogthumb.pstatic.net/MjAyNDEyMTdfMTg3/MDAxNzM0NDIxMDc5MDU3.Vq057BNFtwOUIrTuQeqzJFAgLYM1XjfGaIL3kwFGhPEg.aHp_oPxeC2oMxNuiX7VEt16BhM4y3aXeduDQlCUA89Qg.PNG/241217_공공saas썸네일.png?type=s3)
공공 SaaS 시장 진출이 목표지만 CSAP 인증 평가가 고민인 기업들 주목! 공공 SaaS 비즈니스에 필수인, CSAP 획득 심사. 어디서부터 시작해야 할지, 막막하셨나요? *CSAP (클라우드 서비스 보안인증) 한국인터넷진흥원 (KISA)에서 지원하는 클라우드 서비스 보안 관련 인증 제도로 공급자가 제공하는 서비스의 정보보호 기준 준수 여부 평가 ...
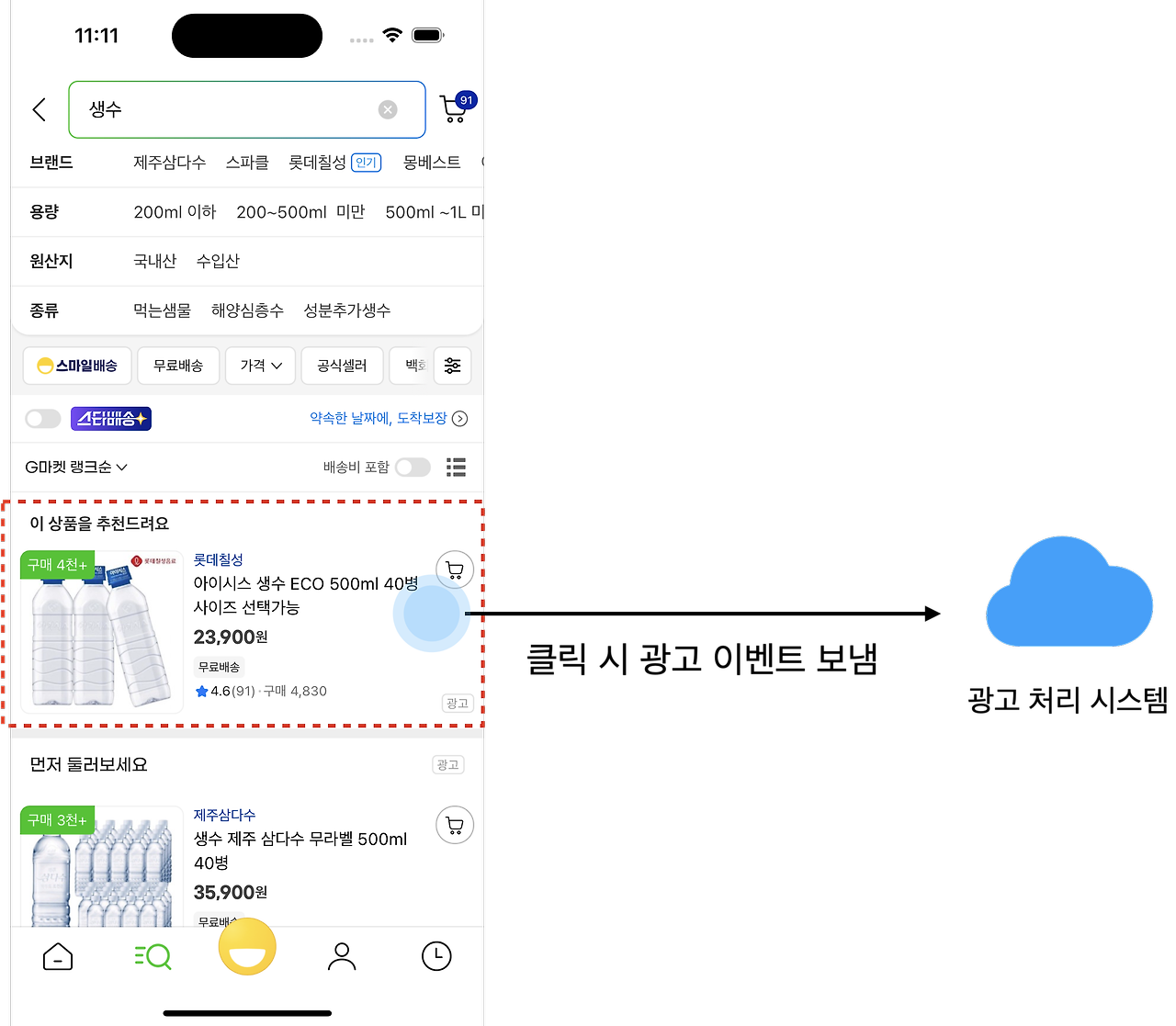
안녕하세요 지마켓 Mobile Application Team 강수진입니다. 오늘은 iOS에서 특정 이벤트에 대한 URL 요청이 정상적으로 이루어졌는지 확인하는 방법에 대해 알아보겠습니다. 들어가기 전에 모든 서비스에서 광고는 중요합니다. 왜냐하면 수익과 직결되기 때문이죠 지마켓도 곳곳에 다양한 유형의 광고가 포함되어 있는데요! 일례로...
들어가며 LINE Plus의 MPR(Mobile Productive & Research) 팀은 LINE 클라이언트 앱의 빌드 개선과 CI 파이프라인 관리, 자동화 지원 등의 업무를...
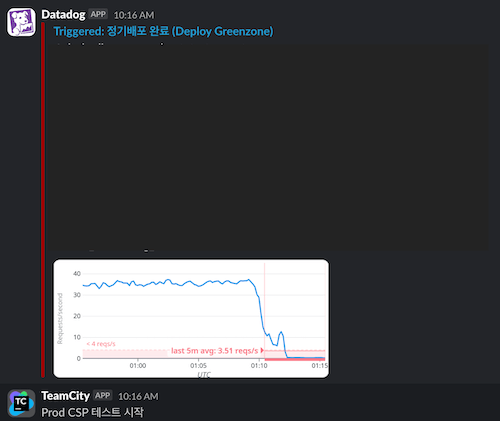
요즘 QA…
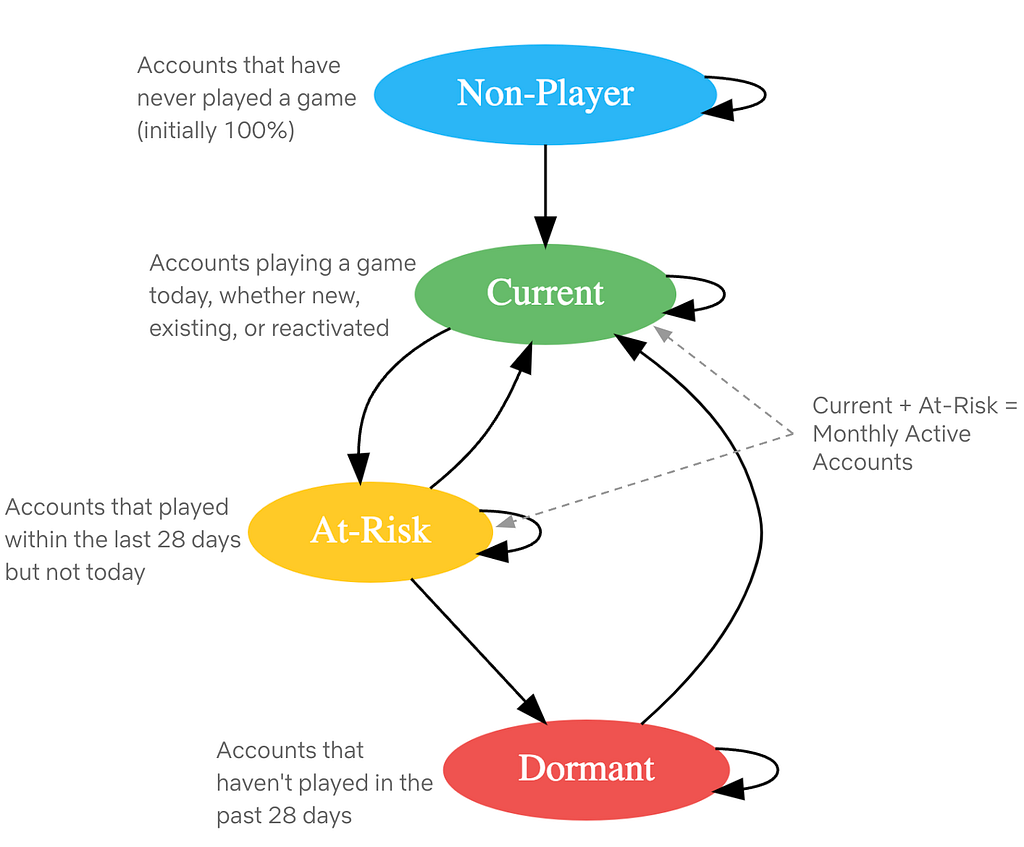
This article is the second in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. Nee...
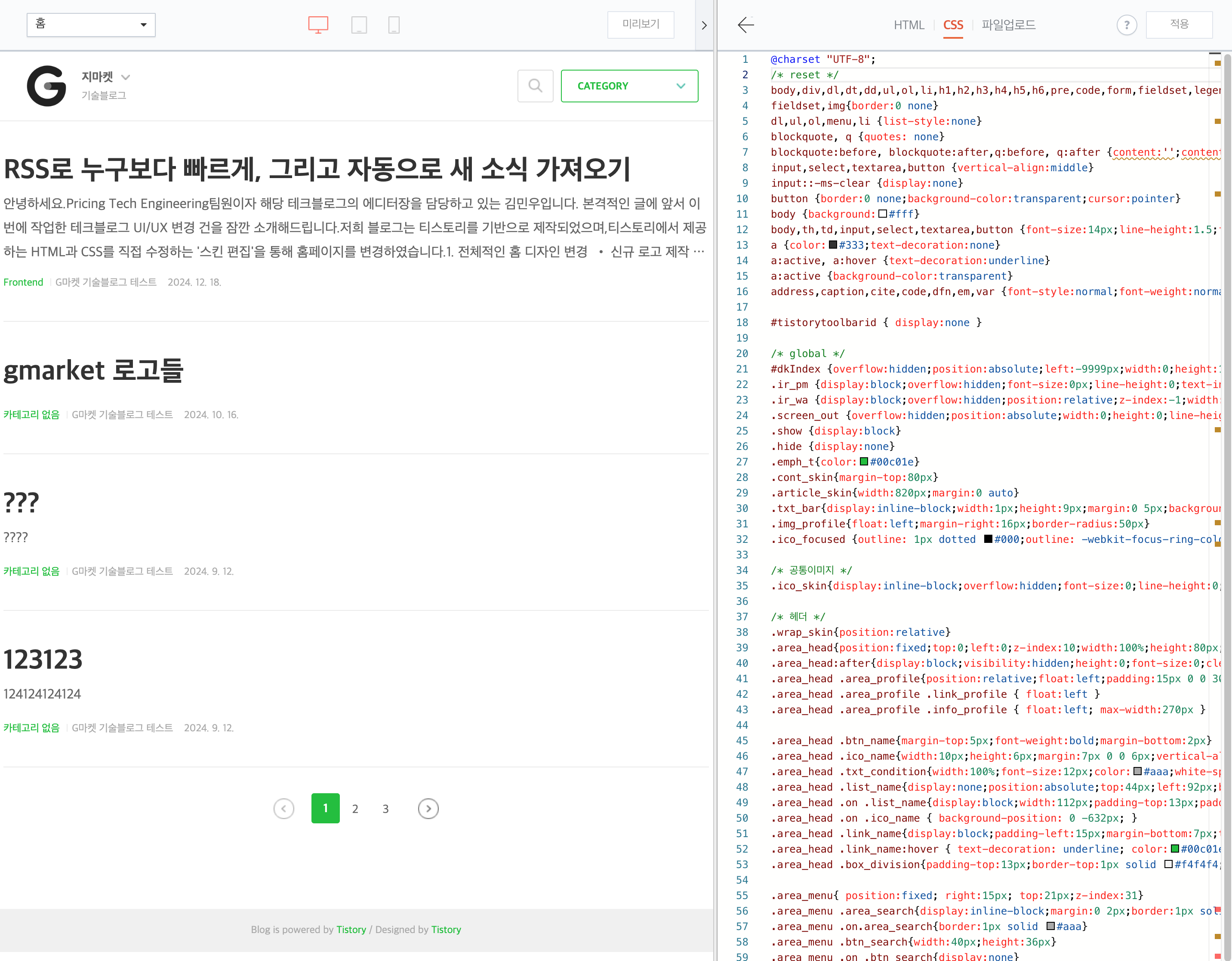
안녕하세요.Pricing Tech Engineering팀원이자 해당 테크블로그의 에디터장을 담당하고 있는 김민우입니다. 본격적인 글에 앞서 이번에 작업한 테크블로그 UI 변경 건을 잠깐 소개해드립니다. G마켓 테크블로그는 티스토리를 기반으로 제작되었으며, 티스토리에서 ...
![[캘린더️] 1월 무료 교육 웨비나 일정 모음](https://blogthumb.pstatic.net/MjAyNTAxMDJfMjU2/MDAxNzM1Nzg1MjMwODEz.lrRl3k0HChhr0s7dNQHY689INJu8VD8moTXF23ek_F4g.bEXTCsFkHS4kYjWjLVN_Pz86HvFv8lWv6xlwV1DPPbMg.PNG/2501_edu_thumb.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com 입니다.
![[웍스 사용 설명서] 중요한 업무 메일 놓치지 않는 법](https://blogthumb.pstatic.net/MjAyNTAxMTVfNzUg/MDAxNzM2OTExMjI5NTk5.8ljmuzBNTKv9lFHFLw6zA0ABO8XOq92ixacHFkk_5OEg.jFQf7gR_p3B8BRoQ_C6zEQ2STjExdh-TVb6Po4iANo0g.JPEG/웍사설메일.jpg?type=s3)
안녕하세요, 협업과 소통을 위한 필수 기능으로 글로벌 53만 기업의 든든한 협업툴 역할을 해온 네이버웍스(NAVER WORKS)입니다! 정신없는 업무 시간, 하루에도 수십 통씩 쏟아지는 메일들을 어떻게 관리하고 계시나요? 메일을 읽었지만 즉시 회신하기 어렵거나 메일로 요청받은 업무를 바로 처리하기 불가능한 경우, 받은 메일함에 용도/목적이 다른 메일들...

딜리버리 프로덕트 개발팀에서 안정적인 서비스 제공을 위한 고군분투기

…
지난 2편에서는 가상 스레드(virtual thread)의 컨텍스트 스위칭(context switching)이 구체적으로 어떤 과정으로 진행되는지 알아봤습니다. 마지막 3편에서는 ...
![[네이버클라우드 아카데미] 건양대 SW중심대학과 성황리에 마무리한 <클라우드 Literacy 과정> 수료식](https://blogthumb.pstatic.net/MjAyNDEyMjRfMTUx/MDAxNzM1MDMxMTEyMjA1.abQCzsyndyvramhX0gOj1HYQBJYdSNe3e0DCbSaI6TQg.zDkx9n7nWRoZrxZihLgZon3p09XS2jk-pC8QB6zLulAg.PNG/썸네일.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버 클라우드 플랫폼 ncloud.com입니다. #네이버클라우드 #네이버클라우드아카데미 #건양대SW중심대학 #NCA클라우드 자격증 교육 지난 11월 29일 금요일, 건양대 SW중심대학과 함께한 첫 번째 과정 수료식이 개최되었습니다. 이번 수료식은 건양대 SW 중심대학과 함께한 네이버클라우드 아카데미의 첫 번...
![[술술 읽히는 업무 해설집 - 근태편] 연차 언제까지 쓸 수 있게 하나요?](https://blogthumb.pstatic.net/MjAyNTAxMTVfODEg/MDAxNzM2OTExMjUzMzI1.fWFLyXc0wwF3M12-kGeU3-ccmTApm4w2oFDnRkgFC0Ag.DVGOTEfYjvAeplbjKxfkmeEt4uAvs11l1E6CiAwlMKAg.JPEG/술술.jpg?type=s3)
안녕하세요, 협업과 소통을 위한 필수 기능으로 글로벌 53만 기업의 든든한 협업툴 역할을 해온 네이버웍스(NAVER WORKS)입니다! "업무와 관련된 것이라면 뭐든지 쉽게 풀어드립니다!" 술술 읽히는 업무 해설집 내년도 연차를 올해 미리 당겨 쓸 수 없나요? 올해 남은 연차는 내년에 이어서 사용할 수 있나요? 연말이 다가오면 인사 담당자가 직원들로부...
![[고객사례] 로커스, "네이버웍스는 로커스의 온전한 업무 몰입을 위한 임직원 복지입니다."](https://blogthumb.pstatic.net/MjAyNDEyMThfMjky/MDAxNzM0NTA2MDk3NzE5.I2lxY8FEG9HW7EGe7i5KXB9_ePWotgdx_hPWlmmu8ngg.ZWUffCZO0czHO2jmxeHxQWJv-zz8rGoU-p5-BYIFPrQg.PNG/네이버클라우드_블로그_썸네일.001.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드 ncloud.com 입니다. 이번 포스팅에서는 네이버웍스를 통해 맞춤형 업무 몰입 환경을 구축한 '로커스'를 소개해 드리려고 해요! 로커스는 극장용 애니메이션부터 광고, 드라마, 미디어아트까지 다양한 분야에서 고품질 콘텐츠를 선보이는 종합 콘텐츠 기업입니다! 로커스 홈페이지 바로 가기 로커스 경...
![[네이버클라우드캠프] 2024 네이버클라우드캠프 서포터즈 발대식 현장](https://blogthumb.pstatic.net/MjAyNDEyMjNfMjQg/MDAxNzM0OTQzNDI1NTQ2.d22-hOR044AT4lbtRks6qSrsxeadQ9ANGHHo6ABKGjAg.CDdz6A0eGJfrF2QIO2wrYAZm6Rd82Z7O-GaKB85FL3Qg.PNG/thumv_1223.png?type=s3)
안녕하세요, 누구나 쉽게 시작하는 클라우드 네이버클라우드(ncloud.com)입니다. #네이버클라우드 #네이버클라우드캠프 #네이버클라우드캠프서포터즈 지난 11월 15일 오후, 네이버 그린팩토리에서 '2024 네이버클라우드캠프 서포터즈 발대식'이 진행되었습니다. 이번 모집에서는 치열한 경쟁률을 뚫고, 총 48명의 서포터즈가 최종 선발되었는데요! 서포터즈...

시니어 UX 설계 가이드라인을 만들기 위해, 리서치로 시니어 사용자들의 공통된 사용성 패턴을 찾는 과정을 들려드릴게요.
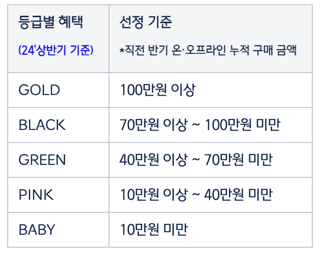
…
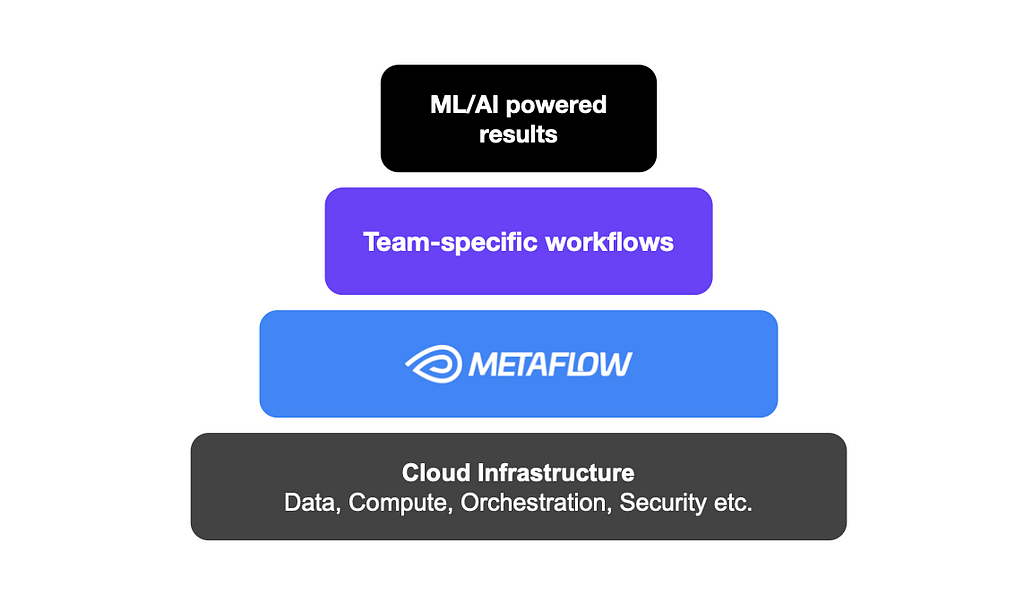
David J. Berg*, David Casler^, Romain Cledat*, Qian Huang*, Rui Lin*, Nissan Pow*, Nurcan Sonmez*, Shashank Srikanth*, Chaoying Wang*, Regina Wang*, Darin Yu**: Model Development Team, Machine Lear...
들어가며 지난 1편에서는 가상 스레드(virtual thread)의 장점을 살펴보고 가상 스레드를 어떻게 생성하고 시작하는지 알아봤습니다. 이어서 이번 글에서는 컨텍스트 스위칭(c...

부제: CloudFront를 동적 콘텐츠에도 사용해보세요~!CloudFront에 대한 고정관념CloudFront에 대해 흔히 가지고 있는 두 가지 오해가 있습니다:정적 콘텐츠만의 영역이라고 생각 하는점.HTML, CSS, JavaScript, 이미지, 미디어 파일과 같은 정적 자원을 빠르게 전송하기 위한 도구로만 인식동적 콘텐츠 처리에는 부적합 하다는...
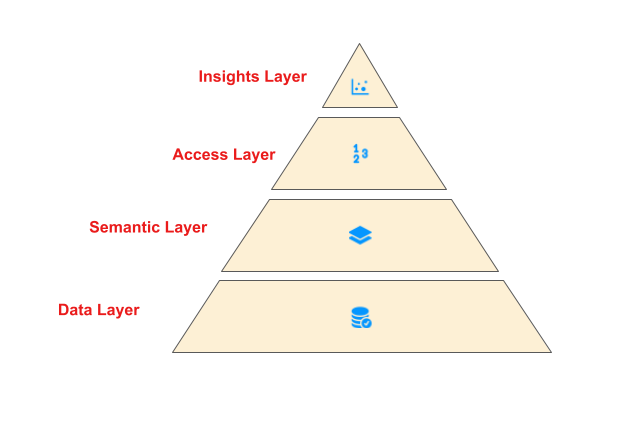
This article is the first in a multi-part series sharing a breadth of Analytics Engineering work at Netflix, recently presented as part of our annual internal Analytics Engineering conference. We k...

DX본부 커뮤니티 DXCO 연말 컨퍼런스가 새롭게 오픈한 GS역삼타워 사내행사 공간에서많은 분들의 참여와 호응 속에 성공적으로 마무리되었습니다! 이번 컨퍼런스는 하반기 동안 열심히 달려온 소모임 활동을 돌아보고,함께 성장과 교류의 의미를 되새긴 뜻깊은 자리였는데요~ 지금부터 그 열정 가득했던 현장을 생생하게 소개합니다! ✨ 잠깐, DXCO...
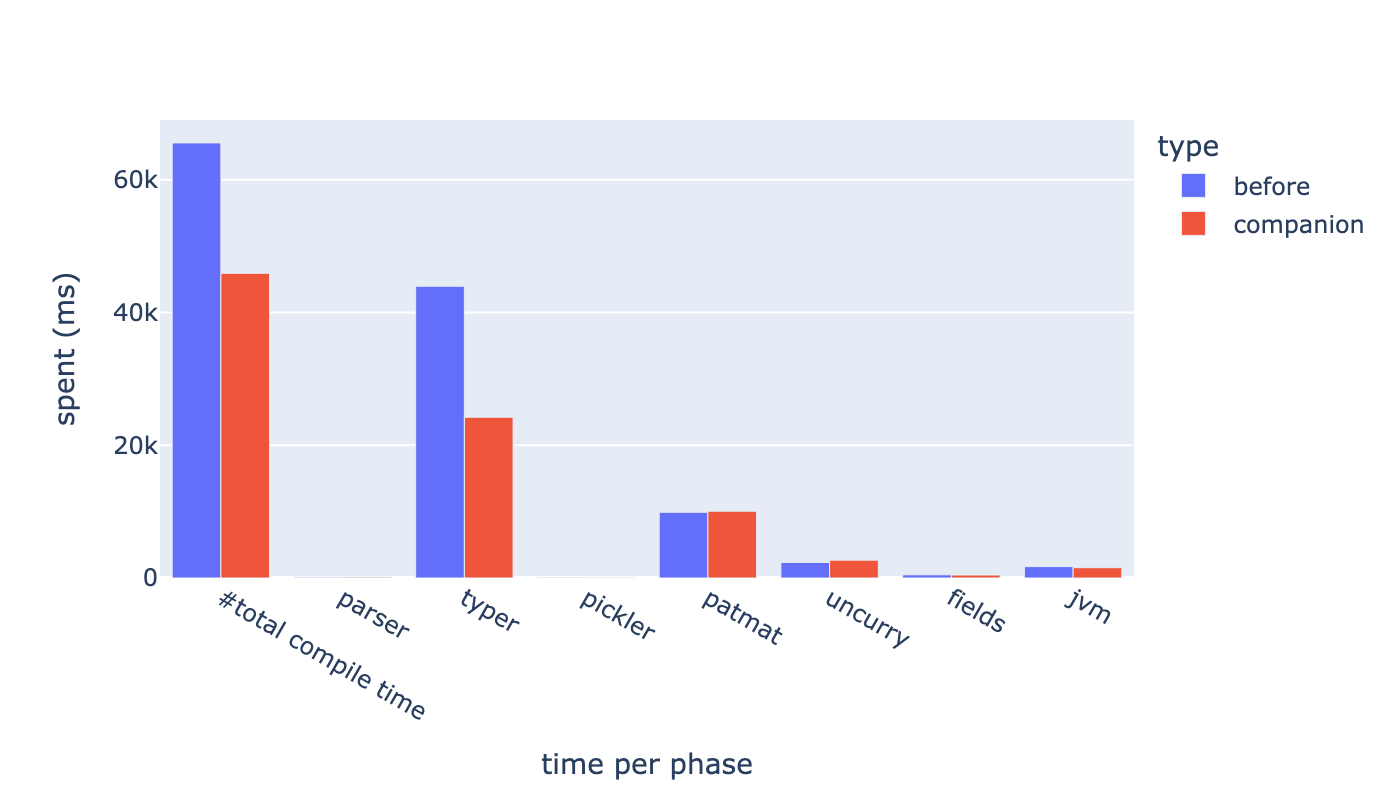
스칼라 프로젝트의 고질적인 문제인 컴파일 속도를 향상한 경험을 공유합니다.

…
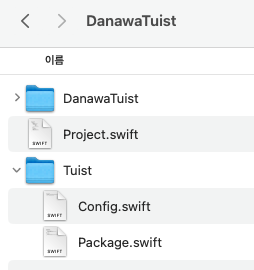
안녕하세요 커넥트웨이브 통합App개발팀 iOS Platform Developer로 일하고 있는 최인호입니다. 오늘은 PC견적의 대변화 중에서 Tuist 관련된 이야기를 하고자 합니다. 기존의 PC견적 다나와 PC견적 iOS앱은 2012년 4월 23일에 세상에 나와, 벌써 출시된 지 12년이 넘은 앱입니다. 다나와 PC 견적은 10만 개의 풍부한 상품 ...
들어가며 Java의 가상 스레드(virtual thread)는 효율적인 동시성 애플리케이션을 개발하기 위해 설계된 경량 스레드입니다. 기존의 Java 스레드 모델과 비교해 더 적은...