![[클로바 시선 #36] 토큰 한 알의 질주: LLM 서빙의 모든 것 (1)](https://blogthumb.pstatic.net/MjAyNTExMDdfNzEg/MDAxNzYyNTA0MTAzODky.ItK_tKVsRb3ZrUeb82BXvyd3jvdw_P26OIpT3R5-q7Ug.YMGJfKCNwV7M1WjlRIXBRMSU5ZmkoM0sfrjvxiWSdgUg.PNG/250926_%BC%F6%B4%C9%B9%AE%C1%A6.png?type=s3)
네이버 클라우드
[클로바 시선 #36] 토큰 한 알의 질주: LLM 서빙의 모든 것 (1)
AI
LLM은 어떻게 화면에 ‘첫 글자’를 띄울까? 요즘 가장 뜨거운 기술 키워드를 꼽자면 단연 LLM(Large Language Model)입니다. 질문에 술술 답하고, 소설도 쓰고, 코드까지 짜는 모델의 활약은 하루가 멀다 하고 화제가 되죠. 하지만 화려한 인터페이스 뒤편에 실제로 어떤 일이 벌어지고 있는지, 생각해 본 적 있으신가요? 사용자가 채팅창에...
2025-11-07

![[클로바 스튜디오 Cookbook] RAG의 활용도를 높일 수 있는 Neo4j 기반 GraphRAG Cookbook](https://blogthumb.pstatic.net/MjAyNTExMDVfMTk5/MDAxNzYyMzMzNTg1NzIx.L0RFW7qKk2FZlGOENi-XBkoyaHjLal7BSJ_zod7zAKAg.CL17CqshZa5iW7BbwKXH8_G-xDnxRRev62Hh-BCDUqcg.PNG/thumbnail_graphRAG.png?type=s3)

![[상품] 번역이 필요한 순간 쉽고 빠르게, Papago Translation](https://blogthumb.pstatic.net/MjAyNTExMDNfMjA2/MDAxNzYyMTQ1ODI1NjU3.ajvM8T3nRS4dtGnq09EoD6sFrodyTBZ5InKDMxRo384g.7UNneFjMdqCp4X4WSRBNhr0E4hwiNzaWweFXUcyC2J0g.PNG/251030_%C6%C4%C6%C4%B0%ED.png?type=s3)


![[인프런 신규 강의] AI 활용 프로그래밍 강의 시리즈](https://k.kakaocdn.net/dn/X087V/btsHv5dUIHP/uuKam7eORZAxkho1fL9gO0/img.png)
![[현장 스케치] 부산시 AI 발전 협의회 출범, AI 전문가들의 만남](https://blogthumb.pstatic.net/MjAyNTEwMDJfMTUg/MDAxNzU5Mzg1MTMxMDM2.NEc3TYVCHBLw4ex8PAgEKGV7rE8wFe7PnFkeoxW2FiIg.wGBHFHWTTakfeREYD25DplYpbv3ZEMYYisNoT3Ox9_Ig.PNG/%BA%ED%B7%CE%B1%D7_%BD%E6%B3%D7%C0%CF_%285%29%A4%B7-4.png?type=s3)

![[클로바 시선 #34] AI, 수능에 도전하다: KoNET](https://blogthumb.pstatic.net/MjAyNTA5MjVfMTYy/MDAxNzU4NzgyMDg3ODUw.u7oIS6h1knrKbBxfNedzU2te4HwQiu2VfJdCV4C2J58g.BYH49CZgQSWtj4wQnjtcqaPdvkV60K6LVJTc5gW2_78g.PNG/250910_AI%2C_%BC%F6%B4%C9%BF%A1_%B5%B5%C0%FC%C7%CF%B4%D9__KoNET.png?type=s3)

![[현장 스케치] 네이버클라우드 GPU 위에서 경험한 Agentic AI 개발 - NVIDIA x NAVER Cloud 부트캠프](https://blogthumb.pstatic.net/MjAyNTA5MjJfNjAg/MDAxNzU4NTI3NzA3NDk4.01zsqhewXdev-IfdcJkfkxFBHloDcU3H7E02ArIj4n8g.Upj5gquKWajEsfo-Cyq5tcRefhG0DgCVOz71A-0f3J4g.PNG/%BF%A3%BA%F1%B5%F0%BE%C6_%BD%E6%B3%D7%C0%CF.png?type=s3)
![[Nclouder 수상작] AI 문장 기록 서비스 북카이브: NCP & CLOVA Studio 활용기](https://blogthumb.pstatic.net/MjAyNTA5MjJfMjQ5/MDAxNzU4NTMzMzQ4OTcx.aBqTgOOWNwZF8I0WhS9k03BOWWJwBYT6ffcRXrjVEkwg.PkNpc5WSun-cTZ-QwU3t5xpUzXX9-V-991oSpd8HoHEg.PNG/%C0%E5%B9%CE%BC%AD%B4%D4_%BA%ED%B7%CE%B1%D7%BD%E6%B3%D7%C0%CF.png?type=s3)


![[웨비나] 비즈니스의 성공적인 에이전틱 AI 활용 전략](https://blog.jetbrains.com/wp-content/uploads/2025/09/Social-Share-Blog-1280x720-1.png)

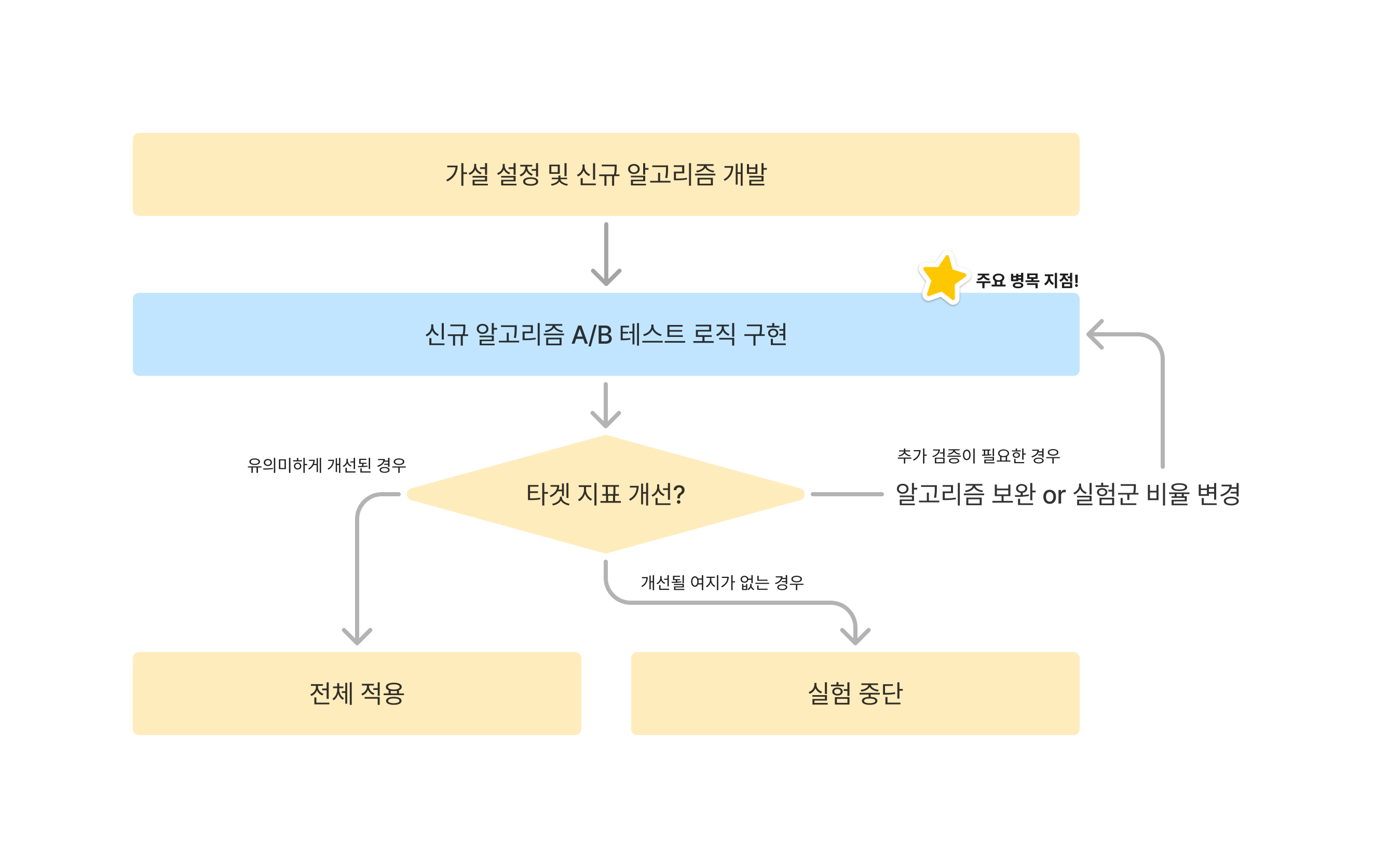


![[클로바 시선 #32] 텍스트 속 트로이 목마: AI 시대, 우리가 놓친 윤리의 경고](https://blogthumb.pstatic.net/MjAyNTA4MDZfMTAz/MDAxNzU0NDU4Nzg5Njk5.FrbAI-l-Z9qBLTJebkeJM7Q0mvnMiCXowKn9VviTPcMg.lqH8AAaLpHw4H9eCGckIdOj56aiYNOgBs8Rv1z3d8N4g.PNG/240826_AI(인공지능).png?type=s3)
![[클로바 스튜디오 Cookbook] 랭체인(Langchain)으로 Naive RAG 구현하기](https://blogthumb.pstatic.net/MjAyNTA4MTFfMTgw/MDAxNzU0OTAyODQxMjk4.wMI9gPiseG_AM-GdmnP_OfYZfscIPifr3OIgjNYKx8cg.4n-jdMTOY99DhW7XFFH6hKA4cH1Jwuz4VV8-y1eLrWQg.PNG/thumbnail_langChain1_0731.png?type=s3)